参考:
https://zhuanlan.zhihu.com/p/338817680
Transformer 模型原理和代码实现教程
一、Transformer 模型简介
Transformer 是一种基于注意力机制的深度学习模型,由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它抛弃了传统 RNN 的循环结构,完全依赖自注意力机制实现序列建模,广泛应用于 NLP 和其他领域。
二、Transformer 模型结构
1. 整体架构
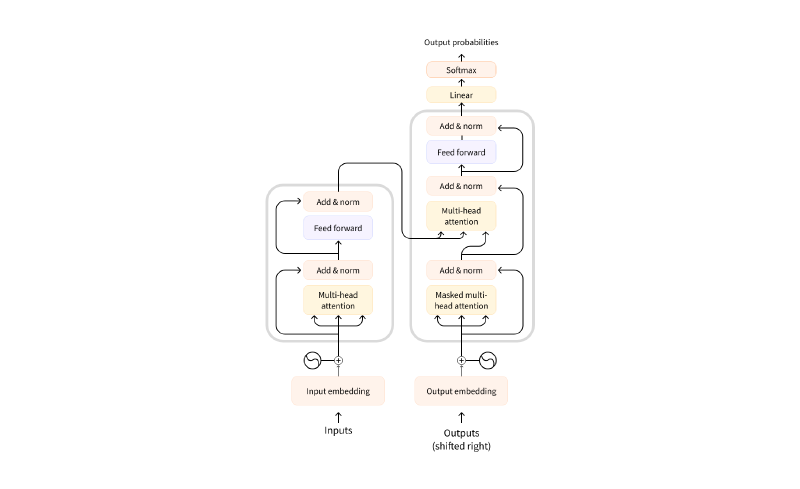
Transformer 由编码器和解码器组成,通常堆叠 6 层,用于序 列到序列任务。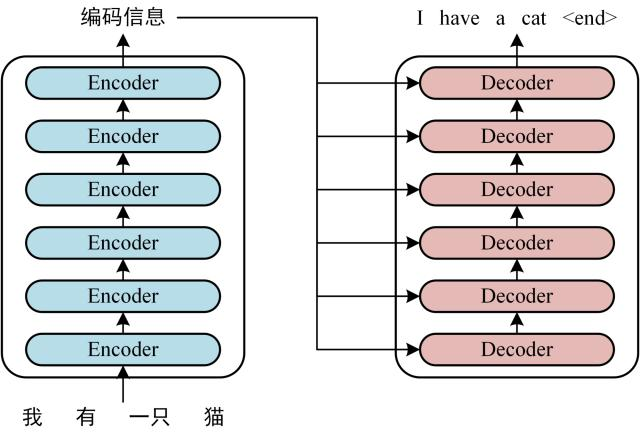
上图展示了编码器和解码器的堆叠结构及数据流向。
2. 编码器(Encoder)
每个编码器层包含:
- 多头自注意力机制
- 前馈神经网络
加上残差连接和层归一化。
3. 解码器(Decoder)
解码器多了掩码自注意力,用于防止未来信息泄露。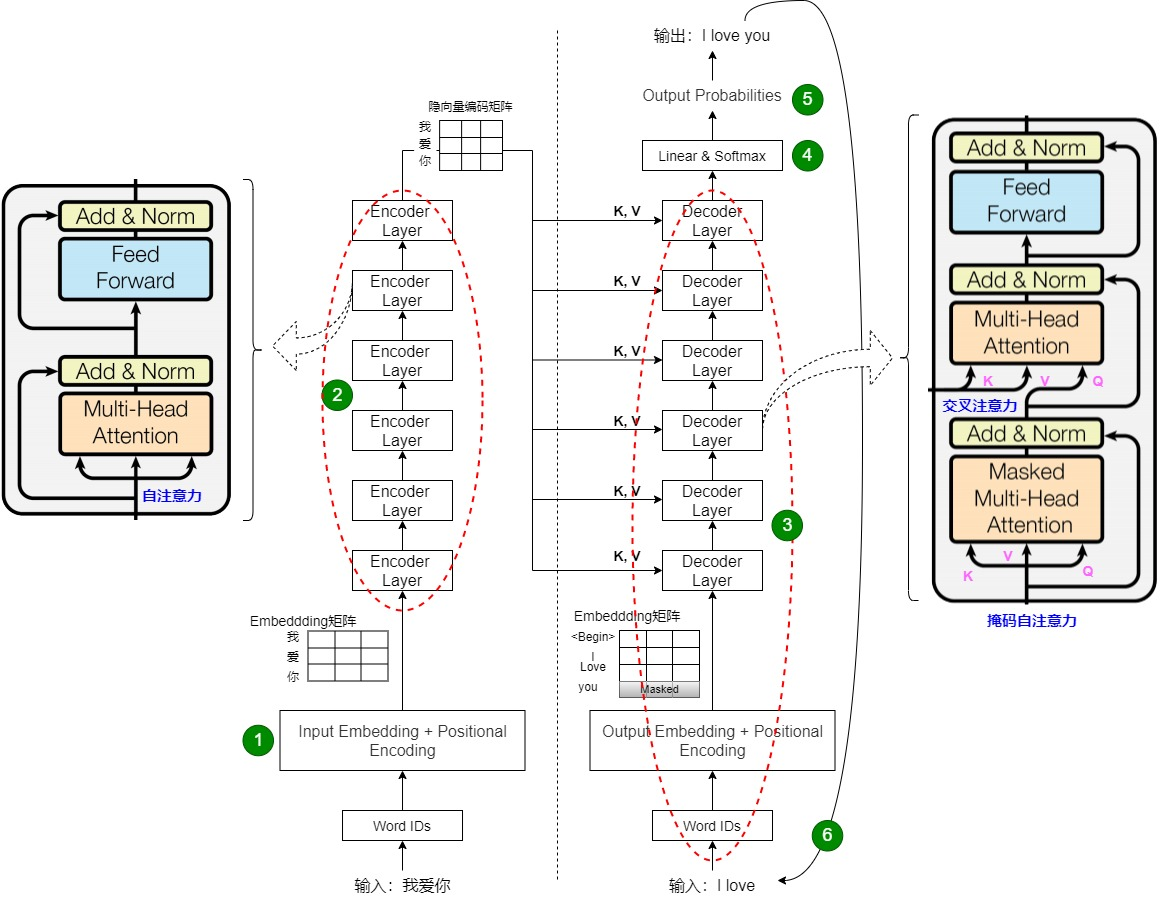 上图详细展示了编码器和解码器层的子模块及连接方式。
上图详细展示了编码器和解码器层的子模块及连接方式。
4. 输入嵌入与位置编码
\[ PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}}) \]\[ PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}}) \]三、自注意力机制(Self-Attention)详解
1. 计算过程
\[ \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \]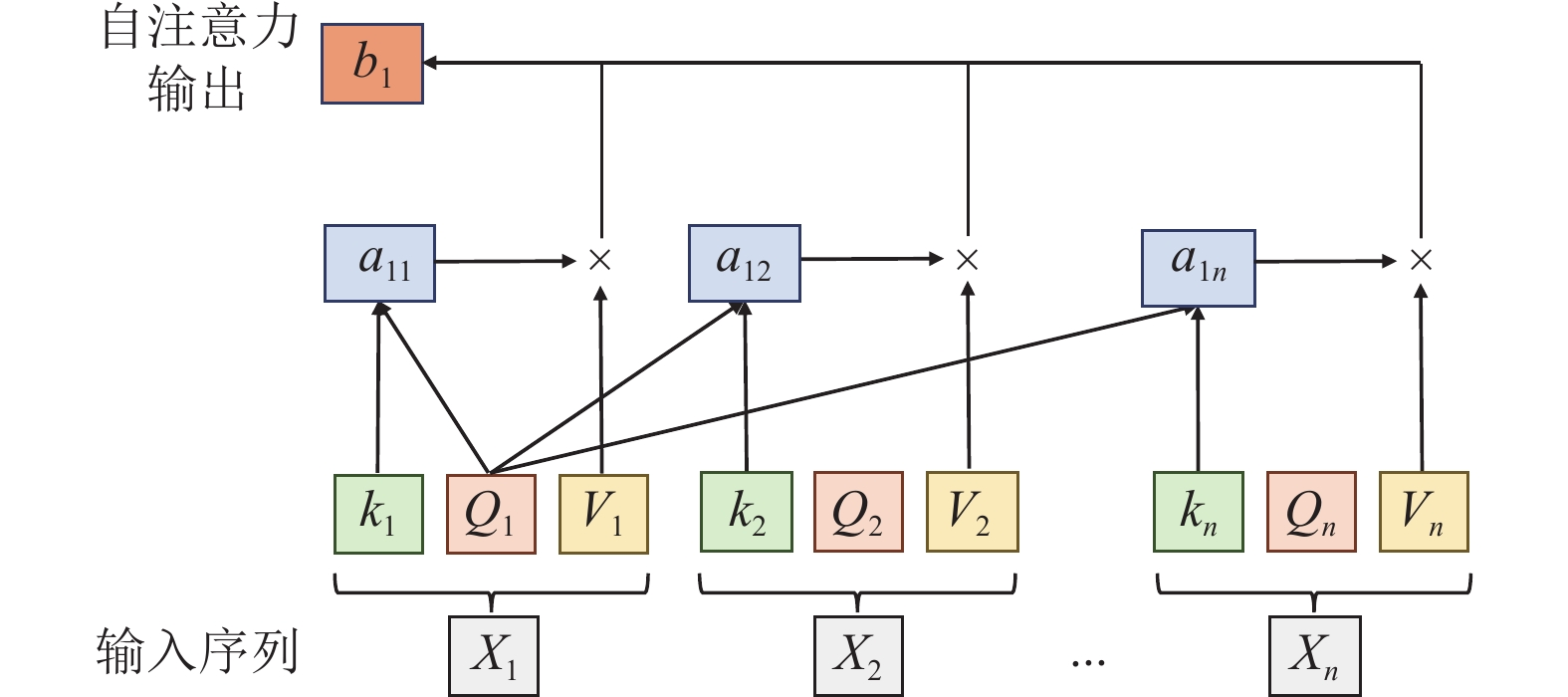 上图展示了自注意力的计算步骤。
上图展示了自注意力的计算步骤。
2. 多头机制
将注意力分成多个子空间并行计算,最后拼接结果。
四、代码实现(基于 PyTorch)
以下是简化的编码器实现:
import torch
import torch.nn as nn
import math
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1), :]
# 多头自注意力
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
q = self.q_linear(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.k_linear(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.v_linear(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = torch.softmax(scores, dim=-1)
context = torch.matmul(attn, v)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
return self.out_linear(context)
# Transformer 编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
# 测试
d_model, num_heads, d_ff, seq_len, batch_size = 512, 8, 2048, 10, 2
encoder_layer = EncoderLayer(d_model, num_heads, d_ff)
x = torch.randn(batch_size, seq_len, d_model)
output = encoder_layer(x)
print(output.shape) # torch.Size([2, 10, 512])