1. 引言
1.1 语言模型的发展历程
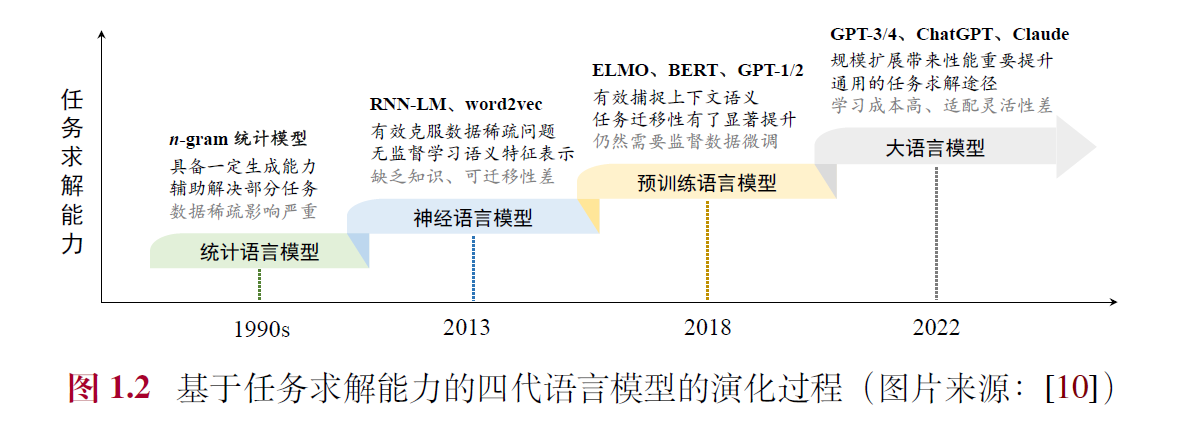
语言模型旨在通过建模人类语言的规律来预测词序列的概率,其发展经历了四个主要阶段:
- 统计语言模型(SLM):20世纪90年代兴起,基于统计方法和马尔可夫假设(如n-gram模型),广泛用于信息检索和早期NLP任务。但受限于数据稀疏和高阶上下文建模能力不足。
- 神经语言模型(NLM):引入神经网络(如RNN)和分布式词表示(词嵌入,如word2vec),克服数据稀疏问题,增强语义表示能力,显著提升了NLP任务性能。
- 预训练语言模型(PLM):基于大规模无标注数据预训练(如ELMo、BERT、GPT-1),引入Transformer架构和“预训练-微调”范式,提升上下文感知和任务迁移能力。
- 大语言模型(LLM):通过规模扩展(如GPT-3、ChatGPT)带来性能跃升,具备涌现能力(如上下文学习),从语言建模转向通用任务求解,成为AI研究热点。
1.2 大语言模型的能力特点
大语言模型相比传统模型展现出显著优势:
- 丰富的世界知识:通过超大规模数据预训练,掌握广泛知识。
- 通用任务解决能力:基于下一个词预测的多任务学习,能解决多样化任务。
- 复杂任务推理能力:在知识推理和数学问题中表现出色。
- 人类指令遵循能力:通过自然语言提示实现任务执行。
- 人类对齐能力:通过强化学习等技术与人类价值观对齐。
- 工具使用能力:可通过微调或提示学习调用外部工具,扩展功能。
1.3 大语言模型关键技术概览
大语言模型的成功依赖以下技术:
- 规模扩展:参数、数据和算力的增加遵循“扩展法则”,提升性能。
- 数据工程:高质量数据采集、清洗和课程设计至关重要。
- 高效预训练:分布式训练(如DeepSpeed)和优化技术支持大规模模型训练。
- 能力激发:指令微调和提示策略(如思维链)激发模型潜能。
- 人类对齐:RLHF等技术确保模型输出符合人类预期。
- 工具使用:通过插件机制扩展模型能力。
1.4 大语言模型对科技发展的影响
大语言模型推动了多个领域的变革:
- 自然语言处理:取代传统任务特定方法,研究转向提升综合能力。
- 信息检索:与搜索引擎融合,形成对话式信息获取模式。
- 计算机视觉:支持多模态模型发展(如GPT-4、Sora)。
- AI4Science:赋能数学、化学等领域的科研创新。 此外,大语言模型改变了科研范式和产业应用,推动通用人工智能(AGI)的探索。
总结
本章回顾了语言模型从统计方法到大语言模型的演化,强调了大语言模型在能力、技术和应用上的突破。它不仅是语言建模的延续,更是AI从专用智能向通用智能跃升的关键,展现了技术规模化与数据驱动的巨大潜力,同时也带来了新的研究与应用挑战。
2. 基础介绍
2.1 大语言模型概述
- 定义:大语言模型是指在海量无标注文本数据上预训练得到的超大规模语言模型,参数规模通常达百亿、千亿甚至万亿(如GPT-3、PaLM、LLaMA),或通过超大规模数据训练的较小模型(如LLaMA-2 7B)。
- 特点:相比传统语言模型,大语言模型采用更复杂的训练方法,展现出强大的自然语言理解和复杂任务求解能力。
- 构建目标:旨在成为通用任务求解器,而非仅针对特定任务优化。
2.2 大语言模型的构建过程
构建大语言模型通常分为两个阶段:
2.2.1 大规模预训练
- 目标:利用大规模无标注文本数据为模型参数找到较好的初始值,压缩世界知识。
- 技术路径:基于Transformer架构(尤其是仅解码器架构)和“预测下一个词”的任务(如GPT系列),已成为主流。
- 数据与算力:
- 需要高质量、多源化的文本数据(当前开源模型常用2-3T词元,趋势仍在扩大)。
- 算力需求极高:百亿参数模型需百卡集群(如A100 80G)训练数月,千亿参数需千卡甚至万卡。
- 挑战:数据清洗、学习率调整、异常检测等经验性技术需研发人员深度优化,避免算力浪费。
2.2.2 指令微调与人类对齐
- 指令微调(SFT):
- 通过任务输入-输出配对数据(模仿学习),激发模型问答能力。
- 数据规模较小(数万至百万条即可),算力需求低(如单机八卡A100数天完成)。
- 人类对齐(Alignment):
- 使用强化学习(如RLHF)增强模型与人类价值观一致性,减少有害输出。
- RLHF需训练奖励模型,基于人类偏好排序,资源消耗介于预训练与微调之间。
- 结果:经过微调与对齐,模型具备较强的人机交互能力,能通过问答解决任务。
2.3 扩展法则(Scaling Law)
扩展法则研究模型性能与规模(模型参数𝑁、数据规模𝐷、算力𝐶)的关系,是大语言模型成功的关键。
2.3.1 KM 扩展法则(OpenAI)
- 公式:性能损失𝐿与𝑁、𝐷、𝐶呈幂律关系(𝐿(𝑁) ∝ 𝑁⁻ᵅᴺ等)。
- 特点:倾向将算力更多分配给模型规模(𝑎≈0.73 > 𝑏≈0.27),认为参数规模提升更重要。
- 意义:提供定量指导,排除架构等次要因素影响。
2.3.2 Chinchilla 扩展法则(DeepMind)
- 公式:𝐿(𝑁,𝐷) = 𝐸 + 𝐴/𝑁ᵅ + 𝐵/𝐷ᵝ,推导出最优分配𝑁opt∝𝐶ᵃ,𝐷opt∝𝐶ᵇ。
- 特点:主张参数与数据规模等比例扩展(𝑎≈0.46,𝑏≈0.54),指出早期模型(如GPT-3)数据不足。
- 实例:Chinchilla(70B参数,1.4T词元)验证了数据规模的重要性。
2.3.3 讨论
- 可预测扩展:小模型可预估大模型性能,早期训练可监控异常,节省算力。
- 任务层面:语言建模损失减少不总对应任务性能提升,某些任务甚至出现“逆向扩展”。
- 数据需求:实际数据需求远超法则估计(如LLaMA-2 7B用2T词元),Transformer架构对数据扩展性强,未达饱和。
2.4. 涌现能力(Emergent Abilities)
- 定义:模型规模达一定阈值时,特定任务性能突然跃升,常见于大模型而非小模型。
- 代表性能力:
- 上下文学习(ICL):无需训练,仅通过提示和示例完成任务(如GPT-3 175B)。
- 指令遵循:经微调后按自然语言指令执行任务(如InstructGPT)。
- 逐步推理:通过思维链(CoT)解决复杂推理问题(如PaLM 540B)。
- 争议:
- 可能因评估指标不连续或模型规模测试有限而夸大。
- 用户感知仍以离散方式为主(如代码正确性),支持涌现能力的实用性。
- 与扩展法则关系:法则预测平滑提升,涌现能力呈现跃升,二者趋势不完全一致。
2.5. GPT系列模型的技术演变
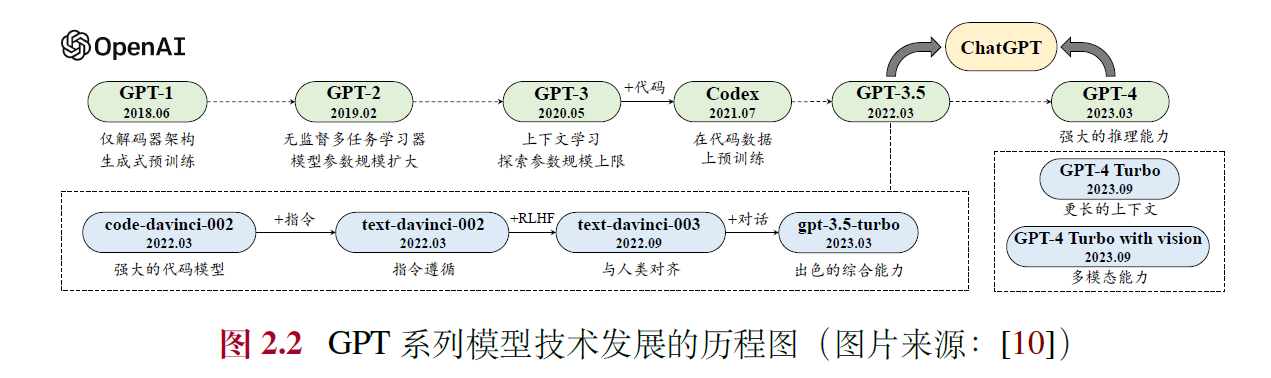
GPT系列由OpenAI开发,经历了四个阶段:
2.5.1 早期探索(GPT-1, GPT-2)
- GPT-1 (2018):基于解码器Transformer,奠定预训练基础,参数较小(~100M),需微调。
- GPT-2 (2019):参数增至1.5B,探索无监督多任务学习,提出语言建模即任务求解。
2.5.2 规模扩展(GPT-3)
- GPT-3 (2020):参数175B,引入上下文学习,确立提示学习范式,验证规模提升性能。
2.5.3 能力增强(GPT-3.5, Codex, InstructGPT)
- Codex (2021):在代码数据上微调,提升编程与推理能力。
- InstructGPT (2022):引入RLHF,增强指令遵循与安全性。
- GPT-3.5:整合代码训练与对齐技术,综合能力提升。
2.5.4 性能跃升(ChatGPT, GPT-4)
- ChatGPT (2022):优化对话能力,支持多轮交互与插件,引发广泛关注。
- GPT-4 (2023):图文多模态,推理能力跃升,安全性增强(如红队攻击)。
- GPT-4 Turbo等:扩展上下文(128K)、多模态支持(视觉、语音),优化性能与生态。
2.6. 总结与展望
- 核心驱动:大规模预训练、指令微调与对齐、规模扩展是LLM成功的基石。
- 挑战:算力依赖、数据稀缺、幻觉与安全性需持续改进。
- 趋势:多模态、更高效训练(如数据合成)、更强泛化能力是未来方向。
3. 大语言模型资源
本章主要介绍了大语言模型研发中可公开使用的资源,包括模型检查点和API、预训练数据、微调数据以及常用代码库。以下是对内容的简要总结,方便您快速把握核心要点:
3.1 公开可用的模型检查点或API
- 背景:预训练大模型需要大量算力和数据,开源模型检查点和商业API极大降低了研发门槛。
- 通用模型检查点:
- LLaMA及LLaMA-2:Meta AI 发布的开源模型,参数规模从7B到70B,广泛用于研究和微调,LLaMA-2支持商用并优化了性能。
- ChatGLM:智谱AI和清华大学开发的中英双语模型,6B参数,支持对话和长文本处理。
- Falcon:TII发布的模型,最高180B参数,是当时最大的开源模型。
- Baichuan及Baichuan-2:百川智能的中英双语模型,7B和13B,支持商用。
- InternLM及InternLM-2:上海人工智能实验室的多语言模型,7B至20B,提供完整工具链。
- Qwen:阿里巴巴的多语言模型,0.5B至72B,支持代码、数学等多模态任务。
- Mistral及Mixtral:Mistral AI的模型,7B至46.7B,采用MoE架构提升效率。
- DeepSeek LLM:幻方公司的中英模型,7B至67B,擅长代码和数学。
- Gemma:谷歌的轻量模型,2B和7B,专注英语任务。
- MiniCPM:面壁智能与清华合作的2B模型,高效且支持多模态。
- YuLan-Chat:中国人民大学的中英模型,最新12B版本经过完整训练流程。
- LLaMA变体系列:如Alpaca、Vicuna等,通过指令微调扩展功能,覆盖基础指令、中文指令、垂域指令和多模态指令。
- 公共API:
- OpenAI:提供GPT-3.5 Turbo、GPT-4等语言模型API,以及text-embedding系列用于文本表征。
3.2 常用的预训练数据集
- 网页:如Common Crawl、C4、RefinedWeb(英文)和ChineseWebText、WanJuan(中文),提供大规模多语言数据。
- 书籍:如BookCorpus、Project Gutenberg,高质量长文本,需注意版权。
- 维基百科:多语言、高质量知识源,支持实时更新。
- 代码:如The Stack、StarCoder,提升模型编程能力。
- 混合型:如The Pile、ROOTS、Dolma,整合多源数据。
3.3 常用微调数据集
- 指令微调:
- NLP任务:P3、FLAN,基于多任务数据集。
- 对话:ShareGPT、OpenAssistant、Dolly,来源于真实用户交互。
- 合成:Self-Instruct、Alpaca,利用大模型生成数据。
- 人类对齐:如HH-RLHF、SHP、PKU-SafeRLHF,关注有用性、诚实性和无害性。
3.4 代码库资源
- Hugging Face:提供Transformers、Datasets、Accelerate,简化模型开发和数据处理。
- DeepSpeed:微软的高性能库,支持分布式训练,包含MII和Chat框架。
- Megatron-LM:NVIDIA的优化库,支持多种并行策略。
- 本书配套:包括LLMSurvey综述、YuLan-Chat模型和LLMBox代码库。
总结
本章全面梳理了大语言模型研发的资源生态,从模型到数据再到代码库,为读者提供了入门和实践的参考。资源的开源共享显著降低了研发成本,推动了技术进步。