DeepSeek-NSA
原文地址: https://arxiv.org/pdf/2502.11089

全文翻译
摘要
Long-context modeling is crucial for next-generation language models, yet the high compu
tational cost of standard attention mechanisms poses significant computational challenges.
Sparse attention offers a promising direction for improving efficiency while maintaining model
capabilities. We present NSA, a Natively trainable Sparse Attention mechanism that integrates
algorithmic innovations with hardware-aligned optimizations to achieve efficient long-context
modeling. NSA employs a dynamic hierarchical sparse strategy, combining coarse-grained
token compression with fine-grained token selection to preserve both global context awareness
and local precision. Our approach advances sparse attention design with two key innovations:
(1) We achieve substantial speedups through arithmetic intensity-balanced algorithm design,
with implementation optimizations for modern hardware. (2) We enable end-to-end training,
reducing pretraining computation without sacrificing model performance. As showninFigure 1,
experiments show the model pretrained with NSA maintains or exceeds Full Attention models
across general benchmarks, long-context tasks, and instruction-based reasoning. Meanwhile,
NSAachieves substantial speedups over Full Attention on 64k-length sequences across decod
ing, forward propagation, and backward propagation, validating its efficiency throughout the
model lifecycle.
Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges. 对于下一代生成式语言模型而言,长文本建模至关重要,然而标准注意力机制的高计算成本带来了显著的计算挑战。
Sparse attention offers a promising direction for improving efficiency while maintaining model capabilities. 稀疏注意力为提高模型能力的同时提供了效率提供了路径。
We present NSA, a Natively trainable Sparse Attention mechanism that integrates algorithmic innovations with hardware-aligned optimizations to achieve efficient long-context modeling. 我们提出了NSA(Natively trainable Sparse Attention),一种原生可训练的稀疏注意力机制,它通过结合算法创新与硬件对齐的优化,实现了高效的长文本建模。
NSA employs a dynamic hierarchical sparse strategy, combining coarse-grained token compression with fine-grained token selection to preserve both global context awareness and local precision. NSA采用了一种动态分层稀疏策略,通过结合粗粒度的标记压缩和细粒度的标记选择,既保留了全局上下文感知能力,又确保了局部精度
Our approach advances sparse attention design with two key innovations: 我们的方法通过以下两项关键创新推动了稀疏注意力机制的设计: (1) We achieve substantial speedups through arithmetic intensity-balanced algorithm design, with implementation optimizations for modern hardware. (2) We enable end-to-end training, reducing pretraining computation without sacrificing model performance. (1) 我们通过算术强度平衡的算法设计以及针对现代硬件的实现优化,实现了显著的加速效果。 (2) 我们实现了端到端训练,在减少预训练计算量的同时不牺牲模型性能。
substantial 实质性的 speedups 加速效果 arithmetic 算术 implementation实现
As shown in Figure 1, experiments show the model pretrained with NSA maintains or exceeds Full Attention models across general benchmarks, long-context tasks, and instruction-based reasoning. 如图1所示,实验表明,使用NSA进行预训练的模型在通用基准测试、长文本任务以及基于指令的推理中,其性能维持或超越了全注意力机制模型。
Meanwhile,
NSA achieves substantial speedups over Full Attention on 64k-length sequences across decoding,
forward propagation, and backward propagation, validating its efficiency throughout the
model lifecycle.
同时,NSA在64k长度序列的解码、前向传播和反向传播过程中,相较于全注意力机制实现了显著的加速,验证了其在整个模型生命周期中的高效性。
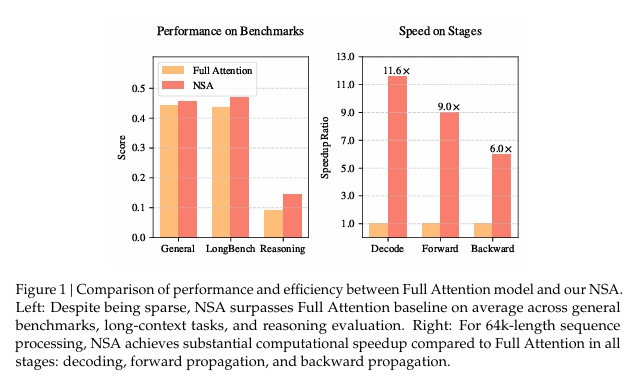
exceeds 超过 instruction-based 基于指令的 reasoning 推理
引言
这篇论文探讨了长上下文建模在下一代大语言模型中的重要性,并提出了一种名为 NSA(Native Sparse Attention) 的新架构,以解决传统注意力机制在处理长序列时的效率瓶颈问题。以下是论文的核心内容概述:
背景与挑战
长上下文建模的重要性:
- 长上下文建模在代码生成、多轮对话、复杂推理等实际应用中至关重要。
- 传统注意力机制(如全注意力)在处理超长序列(如64k tokens)时,计算复杂度和延迟显著增加,成为性能瓶颈。
现有稀疏注意力方法的局限性:
- 尽管已有多种稀疏注意力方法(如KV缓存优化、块级选择、哈希采样等),但它们在实际部署中往往无法实现理论上的加速效果。
- 现有方法主要关注推理阶段,缺乏对训练阶段的支持,难以充分利用注意力的稀疏性。
NSA 的创新点
为了解决上述问题,NSA 提出了两种核心创新:
硬件友好的系统设计:
- 通过分块稀疏注意力优化 Tensor Core 利用率和内存访问模式,确保计算强度均衡,从而将理论计算减少转化为实际速度提升。
支持训练的设计:
- 引入高效的算法和可微分的反向传播算子,使稀疏注意力能够在训练阶段稳定运行,同时降低训练成本。
NSA 的架构
(见图2)
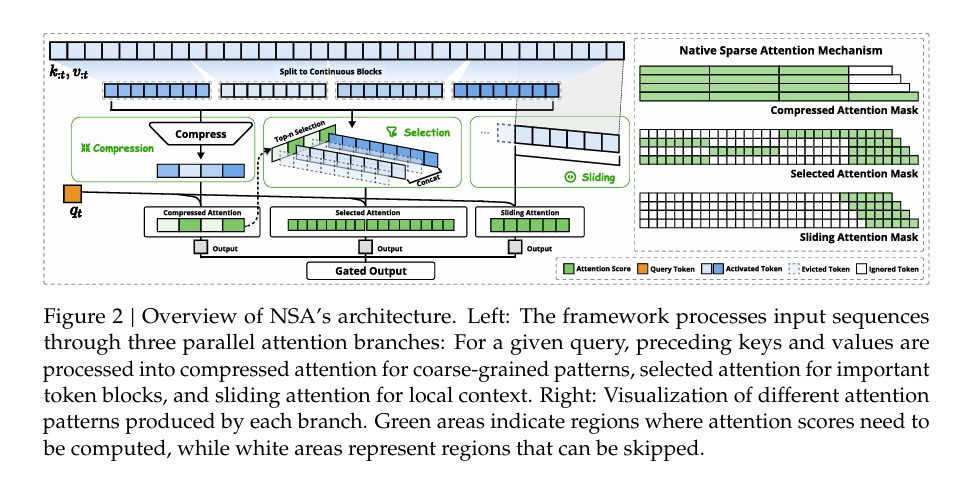
NSA 的架构基于分层稀疏注意力,通过以下三个并行的注意力路径处理输入序列:
- 压缩粗粒度注意力:对先前的键值对进行压缩,捕捉全局模式。
- 选择性细粒度注意力:保留重要的 token 块,捕捉关键信息。
- 滑动窗口注意力:处理局部上下文信息。
这种设计显著减少了每查询的计算量,同时通过专用内核实现高效的实际性能。
实验结果
性能评估:
- 在通用语言任务、长上下文任务和链式推理任务中,NSA 的表现与全注意力基线相当甚至更优。
- 相比现有稀疏注意力方法,NSA 表现出更强的性能。
效率提升:
- 在 A100 GPU 上,NSA 在解码、前向传播和反向传播阶段均实现了显著加速,尤其是对于超长序列(如64k tokens),加速比进一步提高。
对稀疏注意力方法的再思考
这一部分标题为 “重新思考稀疏注意力方法”,深入分析了现代稀疏注意力技术的局限性,并提出了对一种新方法——原生稀疏注意力(NSA) 的需求。文章指出了两个关键挑战:高效推理 和 可训练稀疏性,并解释了为什么现有方法无法充分应对这些挑战。以下是详细总结:
2.1. 高效推理的幻觉
稀疏注意力方法通过选择性处理输入序列中重要的部分来减少计算复杂度。然而,许多方法未能将这种理论上的计算减少转化为实际推理过程中的延迟改进,主要原因有两个:
阶段受限的稀疏性:
- 一些方法(如 H2O)仅在 自回归解码阶段 应用稀疏性,但在 预填充阶段 需要进行昂贵的预处理步骤(如注意力图计算、索引构建)。
- 另一些方法(如 MInference)则专注于预填充阶段的稀疏性,但未优化解码阶段。
- 因此,这些方法无法在所有推理阶段实现加速,至少有一个阶段的计算成本与全注意力相当。这限制了它们在诸如书籍摘要(预填充密集型)或长链推理(解码密集型)等任务中的有效性。
与先进注意力架构的不兼容性:
- 现代架构(如 多查询注意力 MQA 和 分组查询注意力 GQA)通过在多个查询头之间共享键值(KV)缓存来提高效率。
- 许多稀疏注意力方法(如 Quest)为每个注意力头独立选择 KV 缓存子集,这种方法在多头注意力(MHA)模型中表现良好,但在基于 GQA 的模型中变得低效。在 GQA 中,内存访问量对应于同一组内所有查询头选择的并集,导致尽管计算减少了,但内存访问成本仍然很高。
- 这种稀疏注意力方法与先进架构之间的不匹配导致性能不佳。
关键要点:现有的稀疏注意力方法往往无法显著减少延迟,因为它们要么是阶段受限的,要么与现代架构不兼容。
2.2. 可训练稀疏性的神话
虽然稀疏注意力方法在推理中表现良好,但在支持高效训练方面却面临困难。主要存在两个问题:
性能下降:
- 在预训练后应用稀疏性(即后处理稀疏化)会迫使模型偏离其原始优化轨迹。例如,剪枝前 20% 的注意力得分只能覆盖总注意力的 70%,使得预训练模型中的某些结构(如检索头)在推理时变得脆弱。
- 这种不匹配导致从全注意力切换到稀疏注意力时性能下降。
训练效率需求:
- 在长序列上训练大语言模型(LLMs)对于增强模型能力以及适应长上下文任务(如微调和强化学习)至关重要。
- 现有的稀疏注意力方法主要针对推理,未解决训练中的计算挑战。这限制了它们在长上下文建模中的扩展能力。
此外,尝试将稀疏注意力方法应用于训练也面临进一步挑战:
不可训练的组件:
- 方法如 ClusterKV(使用 k-means 聚类)和 MagicPIG(使用 SimHash 选择)涉及离散操作,破坏了计算图,阻止了梯度流通过 token 选择过程。这限制了模型学习最优稀疏模式的能力。
低效的反向传播:
- 技术如 HashAttention 使用基于 token 的细粒度选择,需要从 KV 缓存中加载大量非连续的单个 token。这阻止了像 FlashAttention 这样依赖连续内存访问和块级计算的高效技术的使用。
- 结果是,由于硬件利用率低下,训练效率受到影响。
关键要点:现有稀疏注意力方法不适合训练,因为它们要么引入了不可训练的组件,要么在反向传播中效率低下。
2.3. 原生稀疏性的必要性
在 推理效率 和 训练可行性 方面的局限性表明,稀疏注意力机制需要进行根本性的重新设计。作者提出了 NSA(原生稀疏注意力),一个旨在解决这些挑战的框架,具体包括:
确保计算效率:
- NSA 集成了硬件友好的设计,在预填充和解码阶段最大化加速。
支持可训练稀疏性:
- NSA 通过引入高效的算法和反向传播算子,允许梯度流动并优化稀疏模式,从而实现端到端训练。
关键要点:NSA 是一个原生稀疏注意力框架,平衡了计算效率和训练需求,克服了现有方法的局限性。
总结
本节批判了现代稀疏注意力方法,指出它们无法在推理阶段提供一致的加速,并且缺乏对高效训练的支持。这些不足促使了 NSA 的开发,这是一种新框架,解决了计算和训练方面的挑战。NSA 通过硬件对齐的系统设计和可训练稀疏性,为更高效、更可扩展的长上下文建模铺平了道路。
方法
该文档描述了一种名为NSA(Natural Sparse Attention)的技术方法,旨在优化注意力机制的计算效率和硬件性能。以下是内容的总结:
1. 背景
- $$ \text{Attn}(q_t, k, v)=\text{Softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) $$
- $$ \mathrm{Attn}(\mathbf{q}_t, \mathbf{k}_{:t}, \mathbf{v}_{:t}) = \sum_{i = 1}^{t} \frac{\alpha_{t,i} \mathbf{v}_i}{\sum_{j = 1}^{t} \alpha_{t,j}}, \quad \alpha_{t,i} = e^{\frac{\mathbf{q}_t^{\top} \mathbf{k}_i}{\sqrt{d_k}}} $$
算术强度:定义为计算操作与内存访问的比率,决定了算法在硬件上的优化方向。训练和预填充阶段通常是计算密集型,而自回归解码阶段则受内存带宽限制。
2. 总体框架
- NSA提出用更紧凑且信息密集的表示(key-value对)替代原始的key-value对,以优化注意力输出。
- 提出了三种映射策略:
- 压缩(Compression):将连续块的keys/values聚合为更高层次的语义表示。
其中$\tilde{K}{t}$、$\tilde{V}{t}$是基于当前查询$q_{t}$和上下文记忆$k_{: t}$、$v_{: t}$动态构建的。
- 选择(Selection):选择最相关的tokens,保留细粒度信息。 我们可以设计各种映射策略来获得不同类别的$\tilde{K}{t}^{c}$、$\tilde{V}{t}^{c}$,并按如下方式组合它们: $$o_{t}^{*}=\sum_{c \in C} g_{t}^{c} \cdot \mathrm{Attn}(q_{t}, \tilde{K}_{t}^{c}, \tilde{V}_{t}^{c})$$
NSA有三种映射策略$C = {cmp, slc, win} $,分别代表键和值的压缩、选择和滑动窗口。$g_{t}^{c} \in [0, 1]$是对应策略$c$的门控分数,通过多层感知机(MLP)和sigmoid激活函数从输入特征中推导得出。
- 滑动窗口(Sliding Window):专注于局部上下文,防止局部模式主导学习过程。
- 这些策略通过动态构造的keys/values实现,并结合门控机制(gate score)进行加权组合。
3. 算法设计 (注意,本节内容没有详细写,需要重新看文章的伪代码)
3.1 Token Compression(压缩)
- 将连续块的keys/values聚合为块级表示,减少计算负担。
- 使用可学习的MLP(多层感知器)和位置编码来生成压缩表示。
3.2 Token Selection(选择)
- 基于块的重要性评分选择最相关的tokens。
- 重要性评分通过压缩tokens的注意力分数推导,支持高效的块级选择。
- 对于共享KV缓存的模型(如GQA/MQA),确保跨头的一致性选择。
3.3 Sliding Window(滑动窗口)
- 维护一个固定大小的窗口,专注于最近的tokens。
- 防止局部模式干扰其他分支的学习,同时引入最小的计算开销。
4. 内核设计
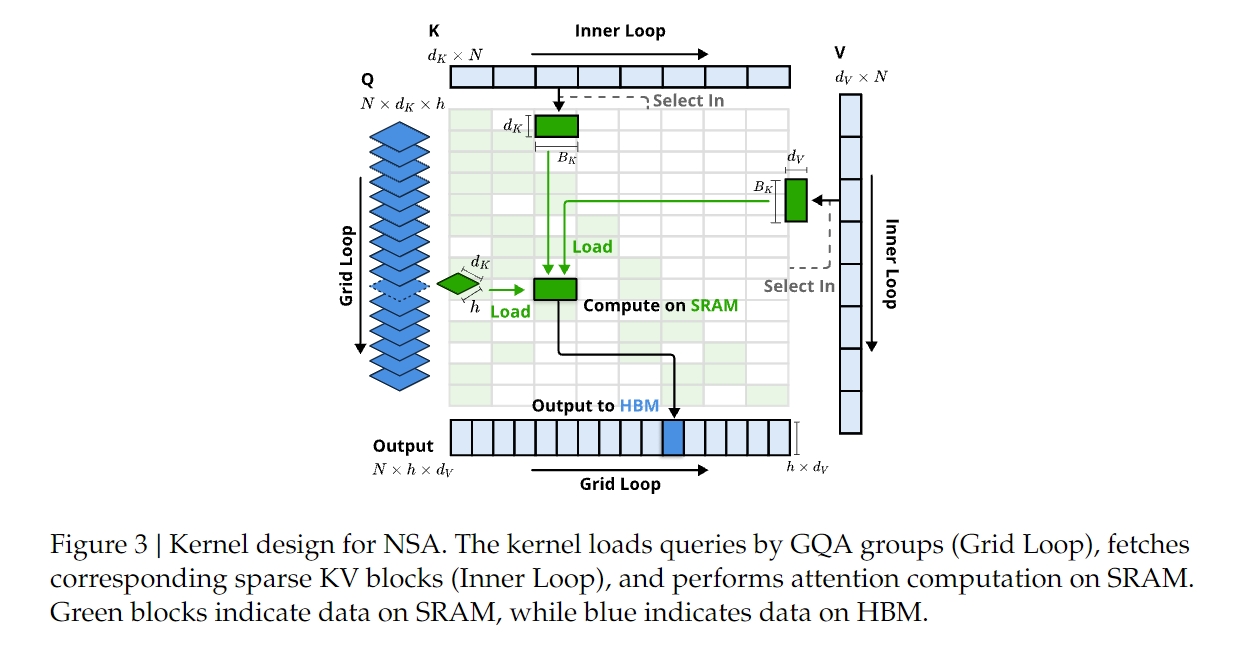
- 在Triton上实现硬件对齐的稀疏注意力内核,优化训练和预填充阶段的速度。
- 核心优化包括:
- 组中心数据加载:按组加载查询(queries),共享稀疏KV块。
- 共享KV获取:按需加载连续的KV块,减少冗余内存传输。
- 外循环调度:利用Triton的网格调度器简化内核设计,平衡GPU流式多处理器的工作负载。
5. 目标
- 训练/预填充阶段:通过压缩和选择策略减少计算成本。
- 解码阶段:通过稀疏KV缓存减少内存访问,提升效率。
总结
NSA通过结合压缩、选择和滑动窗口策略,显著降低了注意力计算的复杂度,同时优化了硬件性能。其内核设计充分利用现代GPU架构特性,实现了接近FlashAttention级别的加速效果。
实验
以下是对上传文件内容的总结:
1. 研究目标
本文通过三个维度评估了一种新的稀疏注意力方法(NSA):(1) 通用基准性能,(2) 长上下文基准性能,(3) 链式思维推理性能。NSA 方法与全注意力(Full Attention)基线和最先进的稀疏注意力方法进行了对比。
2. 模型架构
基础架构:
- NSA 使用了 Grouped-Query Attention (GQA) 和 Mixture-of-Experts (MoE) 的组合。
- 模型参数总量为 27B,其中激活参数为 3B。
- 包含 30 层,隐藏维度为 2560。
- GQA 设置了 4 组,共 64 个注意力头;每个头的查询、键和值的隐藏维度分别为 𝑑𝑞 = 𝑑𝑘 = 192 和 𝑑𝑣 = 128。
- MoE 使用 DeepSeekMoE 结构,包含 72 个路由专家和 2 个共享专家,设置 top-k 专家为 6。
- 第一层的 MoE 被替换为 SwiGLU 形式的 MLP,以确保训练稳定性。
稀疏注意力设计:
- NSA 设计了分层稀疏注意力机制,结合压缩 token 进行全局上下文扫描,以及选择 token 实现局部信息检索。
- 参数设置包括:压缩块大小 𝑙 = 32,滑动步幅 𝑑 = 16,选择块大小 𝑙′ = 64,选择块数量 𝑛 = 16,滑动窗口大小 𝑤 = 512。
3. 实验设置
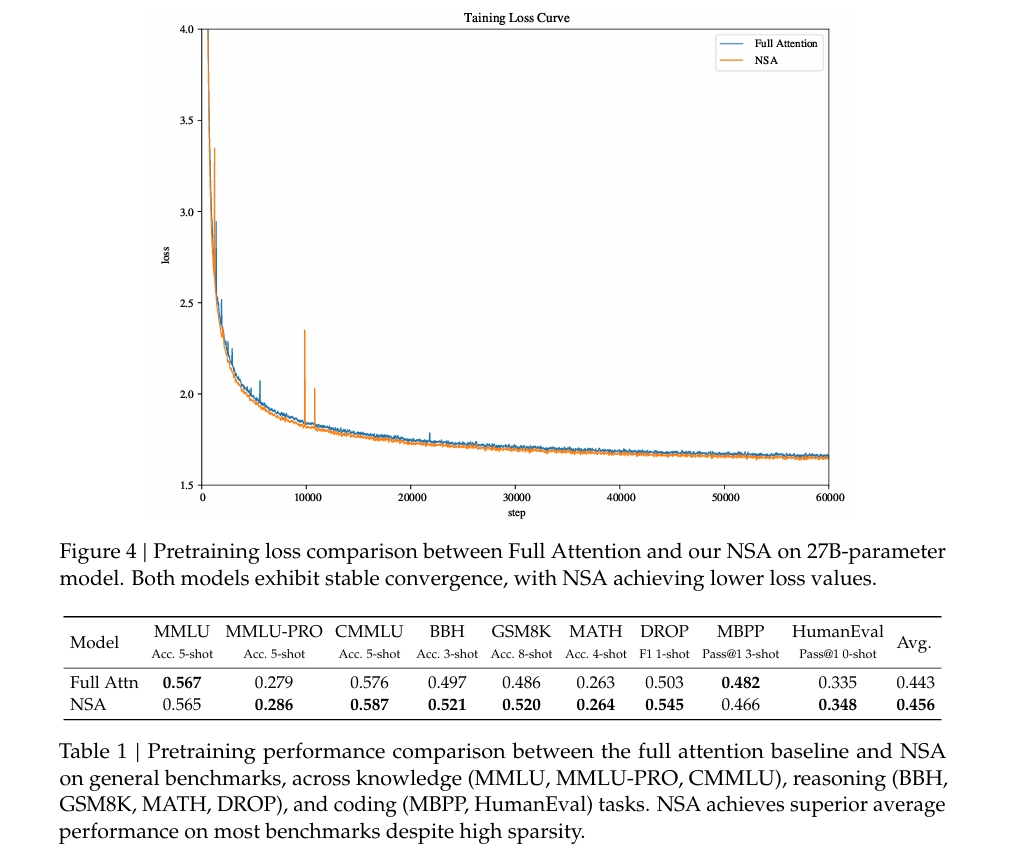
预训练:
- NSA 和 Full Attention 模型均在 270B tokens 的 8k 长度文本上进行预训练,并在 32k 长度文本上进行继续训练和监督微调(使用 YaRN 方法)以适应长上下文。
- 训练至完全收敛,以确保公平比较。
基线方法:
- 对比了多种最先进的稀疏注意力方法(如 H2O、infLLM、Quest 和 Exact-Top),以及 Full Attention 基线。
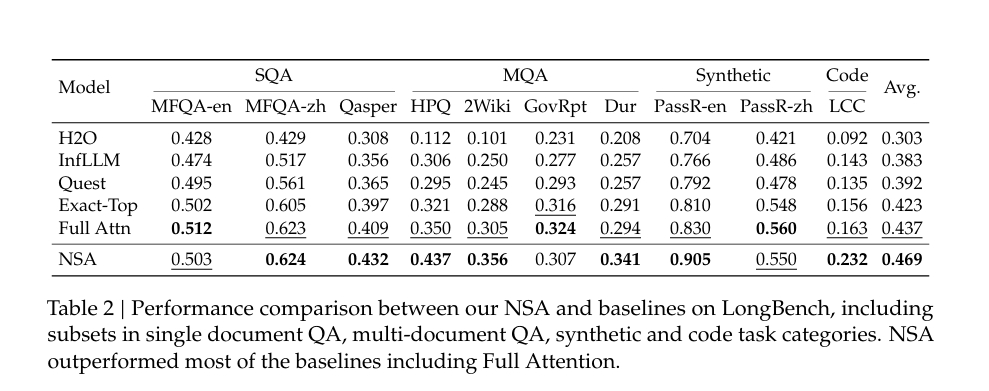
- 对比了多种最先进的稀疏注意力方法(如 H2O、infLLM、Quest 和 Exact-Top),以及 Full Attention 基线。
4. 实验结果
(1) 通用基准性能
- 在知识、推理和编码任务上的多个基准测试中(如 MMLU、BBH、GSM8K 等),NSA 在 7/9 的指标上优于 Full Attention。
- NSA 在推理相关任务(如 DROP 和 GSM8K)上表现尤为突出,分别提升了 +0.042 和 +0.034。
- 结果表明,尽管 NSA 是稀疏注意力模型,但其性能优于 Full Attention,验证了其作为通用架构的鲁棒性。
(2) 长上下文性能
- 在长上下文任务(如 LongBench 和 Needle-in-a-Haystack 测试)中,NSA 表现优异。
- NSA 在 64k 上下文长度的 Needle-in-a-Haystack 测试中实现了完美的检索准确率。
- 在 LongBench 上,NSA 的平均得分最高(0.469),比 Full Attention 提升 +0.032,比 Exact-Top 提升 +0.046。
- NSA 在复杂推理任务(如多跳 QA 和代码理解)上表现出显著优势。
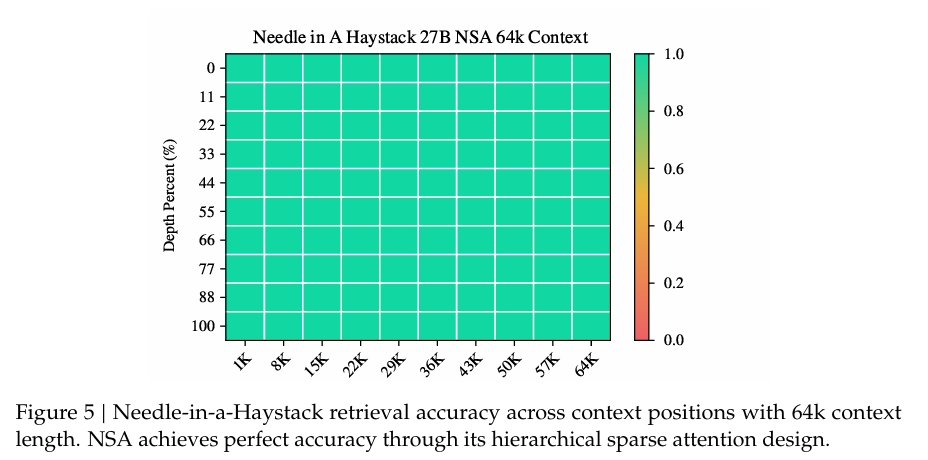
(3) 链式思维推理性能
- 在数学推理任务(AIME 测试)中,NSA-R(NSA 的微调版本)在 8k 和 16k 上下文长度下均优于 Full Attention-R。
- NSA-R 在 8k 上下文中提升 +0.075,在 16k 上下文中提升 +0.054。
- 结果表明,NSA 的稀疏注意力模式能够有效捕获长距离逻辑依赖关系,支持复杂的数学推导。
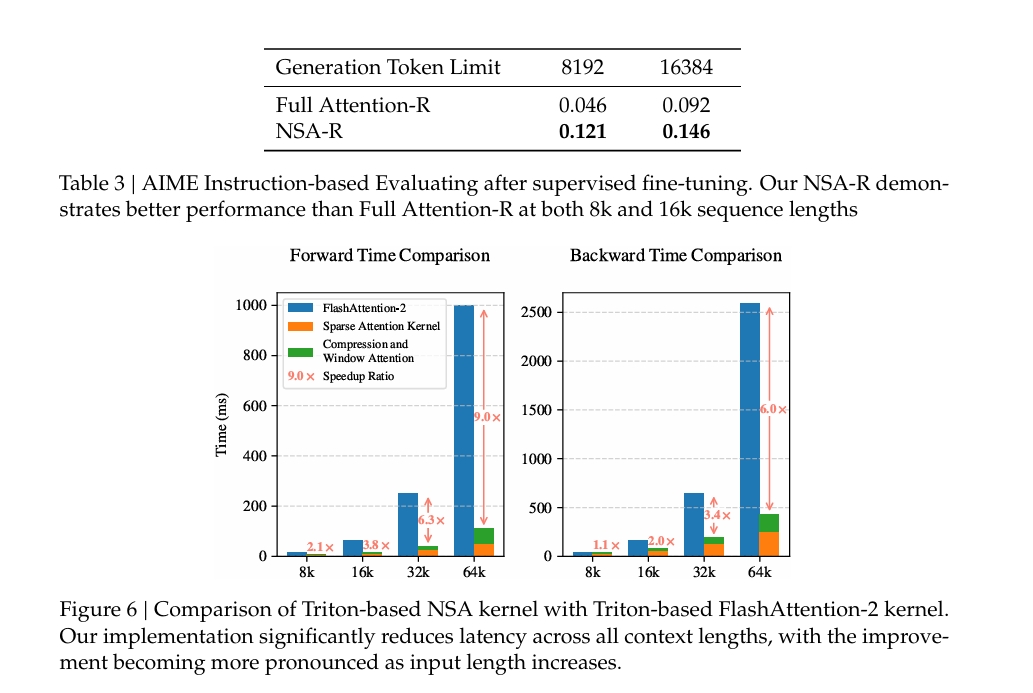
5. 效率分析
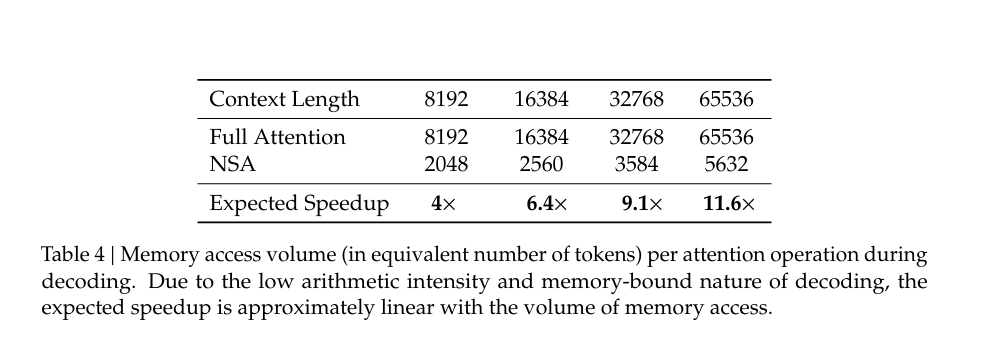
- NSA 的实现显著减少了延迟,特别是在长上下文场景中,改进效果更加明显。
- 在前向传播时间对比中,NSA 的速度比 FlashAttention-2 快 9 倍(在 64k 上下文长度下)。
- 在反向传播时间对比中,NSA 也表现出显著的速度优势。
6. 结论
- NSA 在通用基准、长上下文任务和链式思维推理任务中均表现出色,验证了其在性能和效率之间的有效权衡。
- 分层稀疏注意力机制使 NSA 能够同时保持全局感知和局部精度,适合处理多样化的长上下文挑战。
- NSA 的硬件对齐设计和端到端优化使其成为一种高效的通用架构,适用于先进推理任务。
讨论
总结内容
在本文的讨论部分,作者对新提出的稀疏注意力机制(NSA)的开发过程进行了反思,并探讨了从不同稀疏注意力策略中获得的关键见解。尽管NSA方法展示了良好的性能,但对其替代策略的挑战和注意力模式的分析为未来的研究方向提供了重要的背景。
6.1 替代令牌选择策略的挑战
在设计NSA之前,作者尝试了将现有的稀疏注意力方法应用于训练阶段,但这些方法遇到了各种挑战,促使他们设计了一种新的稀疏注意力架构:
基于聚类的策略(Key-Clustering Based Strategies)
- 例如ClusterKV(Liu et al., 2024),这类方法将同一簇中的Keys和Values存储在连续的内存区域中。
- 挑战:
- 动态聚类机制引入了显著的计算开销。
- 在混合专家系统(MoE)中,由于专家并行性(EP)组执行时间的不平衡,操作优化变得更加困难。
- 必须进行周期性重新聚类以及分块顺序训练协议,这带来了实现上的限制。
- 这些因素共同导致了实际部署中的瓶颈问题。
其他块级选择策略(Other Blockwise Selection Strategies)
- 例如Quest(Tang et al., 2024)和InfLLM(Xiao et al., 2024),这些方法通过计算每个块的重要性得分并选择与查询最相似的前𝑛个块来实现稀疏性。
- 挑战:
- 选择操作是非可微的,因此基于神经网络的重要性得分计算依赖于辅助损失(auxiliary loss),这增加了操作开销并可能降低模型性能。
- 基于启发式的无参数重要性得分计算策略存在召回率低的问题,导致次优性能。
- 实验结果表明,这两种方法在3B参数模型上的表现均不如NSA和全注意力机制(Full Attention)。具体而言:
- 辅助损失方法通过引入额外的查询和代表性键来估计块重要性得分,但效果有限。
- 启发式无参数方法(如Quest)虽然避免了额外参数,但冷启动训练(Cold-Start Training)后仍表现出较高的损失值。
6.2 可视化分析
为了探索Transformer注意力分布中的潜在模式,作者对预训练的27B参数全注意力模型的注意力图进行了可视化(见图8)。
观察到的模式:
- 注意力得分呈现出块状聚类特性,即相邻的Keys往往具有相似的注意力得分。
- 这一现象表明,序列中相邻的令牌可能与查询令牌共享某些语义关系,尽管这些关系的具体性质需要进一步研究。
启发:
- 基于空间连续性的块选择可能是提高计算效率的有效方法,同时能够保留高注意力模式。
- NSA的设计正是受到这种块状聚类现象的启发,旨在通过对连续令牌块的操作而非单个令牌来实现稀疏注意力机制。
总结
通过对替代稀疏注意力策略的挑战和注意力模式的深入分析,作者得出以下结论:
- 现有的稀疏注意力方法在训练阶段面临显著的计算和实现瓶颈,难以满足实际部署需求。
- 注意力分布的块状聚类特性为稀疏注意力机制的设计提供了重要启示,推动了NSA的开发。
- NSA通过基于块的选择策略,在保持高性能的同时实现了更高的计算效率,为未来的稀疏注意力研究提供了新的方向。
相关工作
总结内容
本文在相关工作部分回顾了现有通过稀疏注意力机制提升注意力计算效率的方法,并将其分为三类核心策略:(1) 固定稀疏模式、(2) 动态令牌剪枝 和 (3) 查询感知选择。以下是对每类方法的总结:
7.1 固定稀疏模式(Fixed Sparse Pattern)
- 典型方法:滑动窗口(Sliding Window)
- 查询仅在固定窗口内计算注意力,从而减少内存和计算成本。
- StreamingLLM (Xiao et al., 2023):通过维护两个关键上下文部分(早期令牌的“注意力汇点”和局部上下文窗口)来处理长文本流。
- 局限性:固定的稀疏模式忽略了全局上下文信息,限制了其在需要完整上下文理解的任务中的性能。
7.2 动态令牌剪枝(Dynamic Token Pruning)
- 动态剪枝方法根据令牌的重要性动态减少KV缓存的使用,从而提高解码效率。
- H2O (Zhang et al., 2023b):基于令牌最近的注意力得分动态剔除对未来预测不重要的令牌,降低KV缓存的内存占用。
- SnapKV (Li et al., 2024):通过分析预填充阶段的注意力权重并投票选出重要特征,仅保留最关键的部分。然后结合压缩特征与近期上下文更新KV缓存,确保提示一致性。
- 优点:这些方法能够灵活适应不同任务需求,同时有效降低内存使用。
7.3 查询感知选择(Query-Aware Selection)
- 这类方法根据查询动态选择最相关的键值对块或令牌。
- Quest (Tang et al., 2024):采用块级选择策略,通过查询与键块的坐标最小-最大值的乘积估计每个块的重要性,选择前𝑛个重要块进行注意力计算。
- InfLLM (Xiao et al., 2024):结合固定模式与检索机制,通过维护注意力汇点、局部上下文和可检索块,从每个块中选择代表性键以估计块的重要性。
- HashAttention (Desai et al., 2024):将关键令牌识别问题建模为推荐问题,通过学习函数将查询和键映射到汉明空间。
- ClusterKV (Liu et al., 2024):首先对键进行聚类,然后根据查询与簇的相似性选择最相关的簇进行注意力计算。
总结
现有的稀疏注意力方法通过不同的策略优化了注意力计算的效率:
- 固定稀疏模式(如滑动窗口)简单高效,但因忽略全局上下文而性能受限。
- 动态令牌剪枝(如H2O、SnapKV)通过动态剔除不重要的令牌,显著降低了内存使用,同时保持了上下文的一致性。
- 查询感知选择(如Quest、InfLLM、HashAttention、ClusterKV)通过动态选择与查询最相关的键值对块或令牌,进一步提升了稀疏注意力的灵活性和性能。
这些方法为稀疏注意力机制的设计提供了多样化的思路,同时也揭示了各自的优势与局限性,为未来研究指明了方向。