
LangSmith 是一个用于构建、监控和评估大型语言模型(LLM)应用程序的平台。它与 LangChain 框架紧密集成,但也可以独立使用,帮助开发者调试、测试、评估和监控 LLM 应用,确保应用质量并加速开发迭代过程。
LangSmith简易入门
以下是 LangSmith 的使用教程,希望能帮助你入门:
一、核心概念
- 可观测性 (Observability): LangSmith 的核心功能是提供对 LLM 应用内部运作的深入了解。它能追踪你的应用中发生的每一步,包括 LLM 调用、链 (Chains) 的执行、Agent 的决策过程等。
- 追踪 (Tracing): 记录 LLM 应用中每个组件的输入、输出和执行时间。这对于理解应用行为、诊断问题至关重要。
- 调试 (Debugging): 通过详细的追踪信息,开发者可以快速定位错误、理解非预期行为的原因。
- 评估 (Evaluation): LangSmith 允许你创建数据集,并针对这些数据集运行评估器 (Evaluators) 来衡量模型或应用的性能。这对于比较不同提示 (Prompts)、模型或应用版本的效果非常有用。
- 数据集 (Datasets): 用于评估的输入输出样本集合。你可以手动创建,也可以从生产环境的追踪数据中提取。
- 监控 (Monitoring): 在应用部署后,持续追踪其性能和行为,及时发现并解决问题。
- 组织 (Organization) 和项目 (Projects): LangSmith 允许你创建组织和项目来管理你的工作。一个组织可以包含多个项目,每个项目可以对应一个特定的 LLM 应用。
二、设置 LangSmith
创建账户:
- 访问 LangSmith 官网 并注册一个账户。
- 登录后,你会被引导创建一个组织 (Organization)。
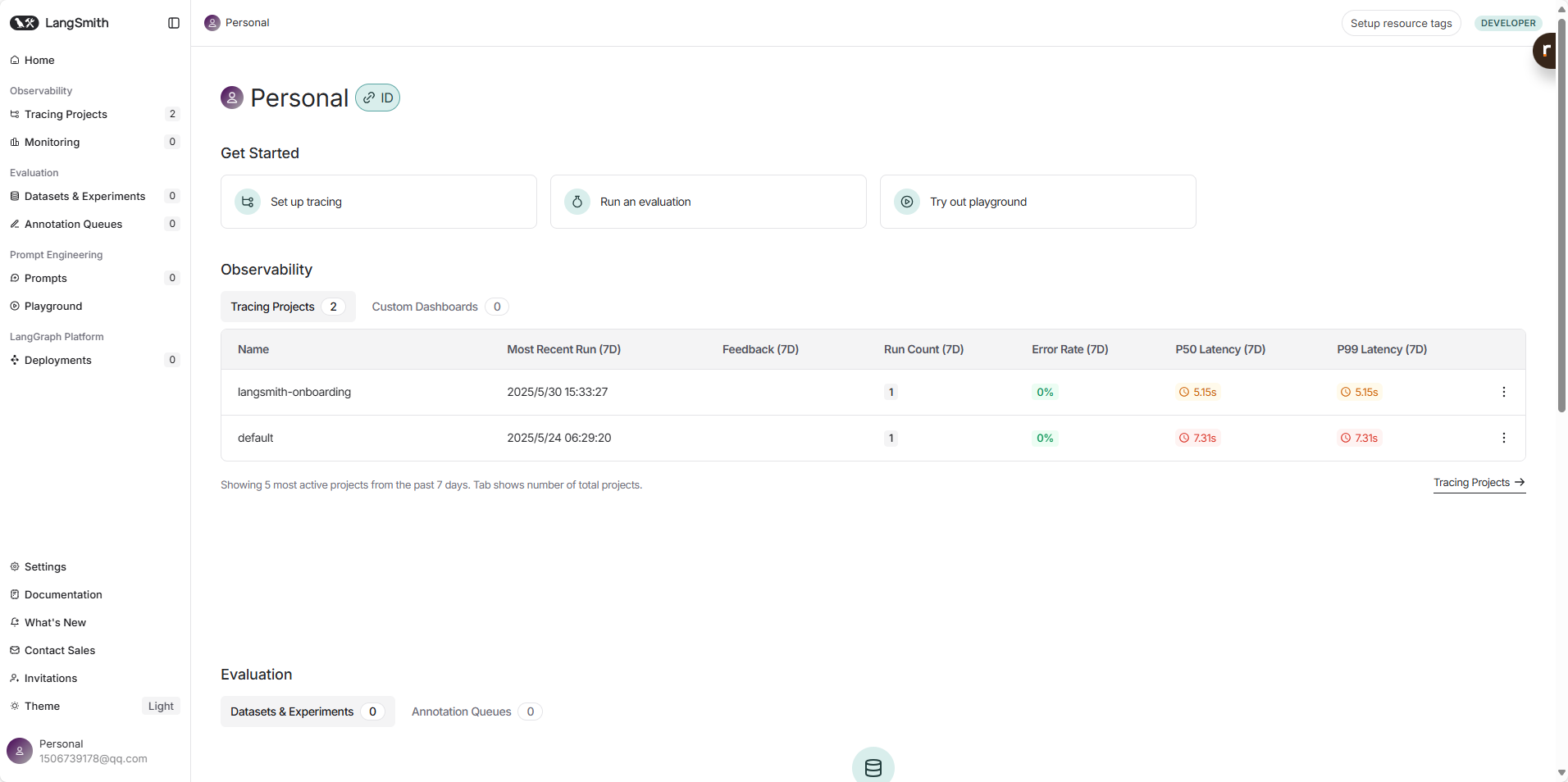
获取 API 密钥:
- 在你的 LangSmith 组织settings中,找到 API 密钥 (API Keys) 部分。
- 创建一个新的 API 密钥。这个密钥将用于在你的代码中授权 LangSmith SDK。请妥善保管此密钥,不要公开分享。

安装 LangSmith SDK:
- 如果你使用 Python,可以通过 pip 安装:
pip install langsmith - 如果你使用 JavaScript/TypeScript,可以通过 npm 或 yarn 安装:
npm install langsmith # 或者 yarn add langsmith
- 如果你使用 Python,可以通过 pip 安装:
设置环境变量:
- 为了让你的应用程序能够与 LangSmith 通信,你需要设置以下环境变量: (可以选存入环境变量中,也可以放入.env当中,然后使用dotenv加载)
export LANGCHAIN_TRACING_V2="true" export LANGCHAIN_ENDPOINT="https://api.smith.langchain.com" export LANGCHAIN_API_KEY="YOUR_LANGSMITH_API_KEY" # 替换为你的 API 密钥 export LANGCHAIN_PROJECT="YOUR_PROJECT_NAME" # 可选,指定项目名称,默认为 "default" LANGCHAIN_TRACING_V2="true": 启用 LangSmith 追踪。LANGCHAIN_ENDPOINT: LangSmith API 的地址。LANGCHAIN_API_KEY: 你的 LangSmith API 密钥。LANGCHAIN_PROJECT(可选): 指定追踪数据发送到的项目名称。如果未设置,将使用名为 “default” 的项目。你可以在 LangSmith 界面创建和管理项目。
- 为了让你的应用程序能够与 LangSmith 通信,你需要设置以下环境变量: (可以选存入环境变量中,也可以放入.env当中,然后使用dotenv加载)
三、基本使用
LangSmith 的主要用途之一是追踪 LangChain 应用的执行。
1. 追踪 LangChain 应用 (Python 示例)
如果你已经设置了上述环境变量,LangChain 应用的追踪会自动启用。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import os
# 确保已设置 LangSmith 环境变量 (如上一节所述)
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
# os.environ["LANGCHAIN_API_KEY"] = "YOUR_LANGSMITH_API_KEY"
# os.environ["LANGCHAIN_PROJECT"] = "My First Project" # 替换为你的项目名
# 定义模型 这里我就使用了阿里的模型
llm = Tongyi(model="qwen-plus-2025-04-28", api_key=os.getenv("DASHSCOPE_API_KEY"))
# 定义提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant that translates {input_language} to {output_language}."),
("human", "{text}")
])
# 定义输出解析器
parser = StrOutputParser()
# 构建链
chain = prompt | llm | parser
# 运行链
try:
result = chain.invoke({
"input_language": "English",
"output_language": "Chinese",
"text": "Hello, how are you?"
})
print(result)
except Exception as e:
print(f"An error occurred: {e}")
print("Please ensure your OpenAI API key and LangSmith environment variables are correctly set.")
运行上述代码后,登录到你的 LangSmith 账户,你应该能在指定的项目下看到这次运行的追踪记录。你会看到链的每个步骤、输入、输出以及可能发生的任何错误。
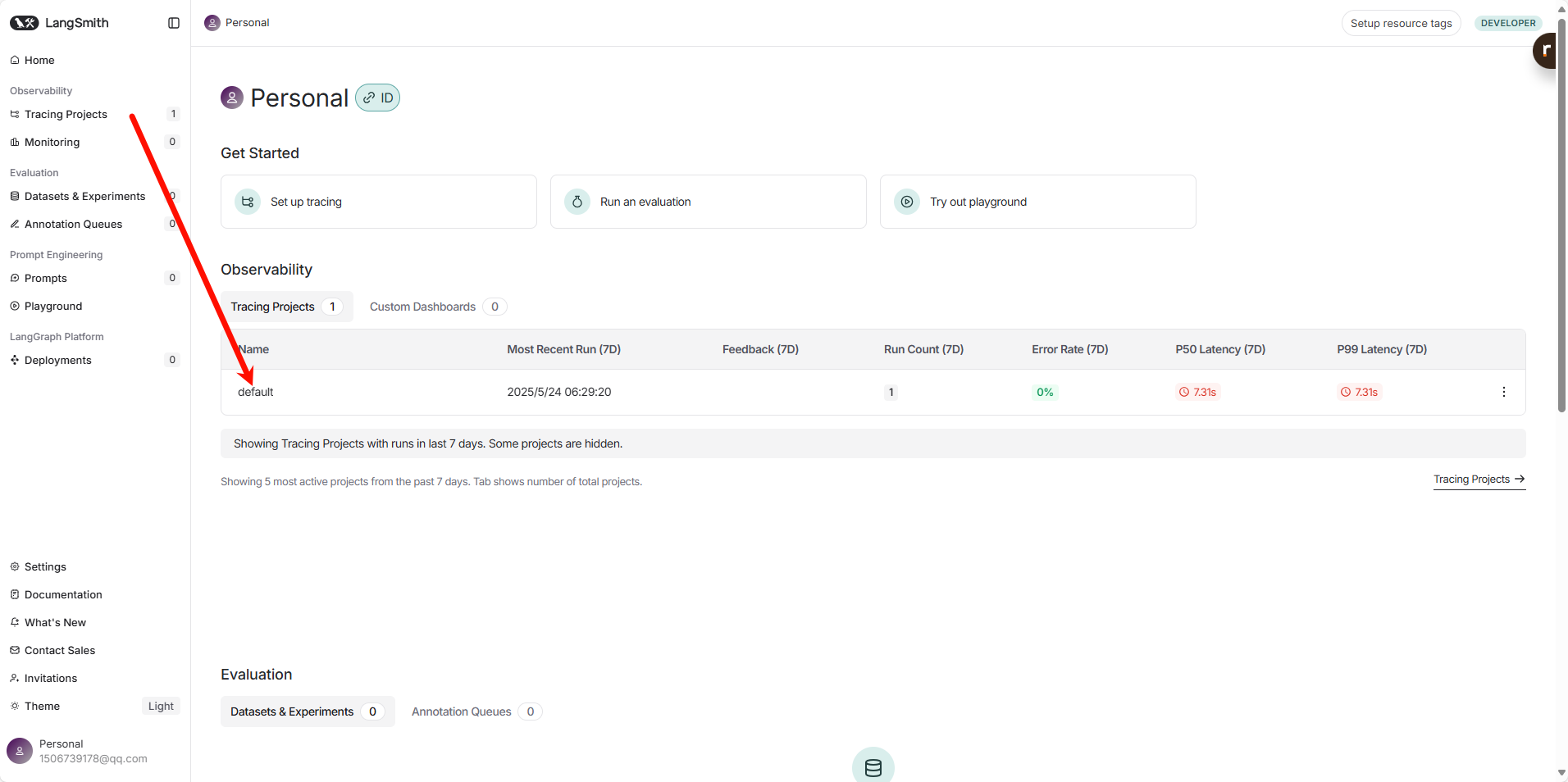
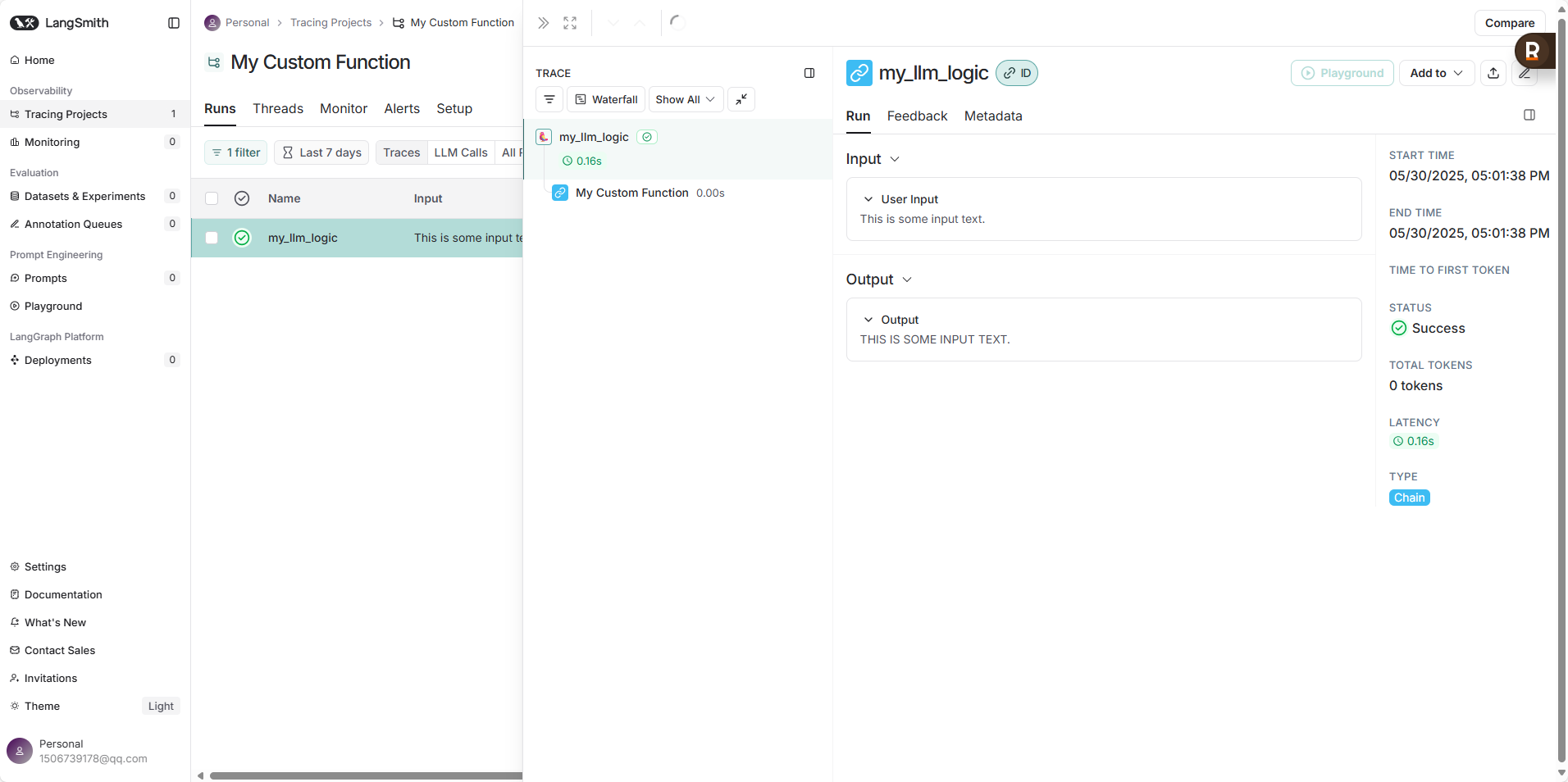
2. 使用 @traceable 装饰器追踪自定义函数 (Python 示例)
你也可以使用 traceable 装饰器来追踪不在 LangChain 链中的函数。
from langsmith import traceable
import os
# 确保已设置 LangSmith 环境变量
# os.environ["LANGCHAIN_API_KEY"] = "..." #你的apikey
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_PROJECT"] = "My Custom Function"
@traceable(name="My Custom Function") # name 参数可选,用于在 LangSmith UI 中显示
def my_data_processing_function(data: str) -> str:
# 假设这里有一些数据处理逻辑
processed_data = data.upper()
return processed_data
@traceable
def my_llm_logic(user_input: str):
# 假设这里调用了 LLM
# from langchain_openai import ChatOpenAI
# llm = ChatOpenAI()
# response = llm.invoke(f"Summarize this: {user_input}")
# processed_input = my_data_processing_function(user_input)
# return response.content
# 为了简化,我们这里只返回处理后的输入
return my_data_processing_function(user_input)
# 调用被追踪的函数
output = my_llm_logic("This is some input text.")
print(output)
四、查看追踪数据
登录 LangSmith 平台后:
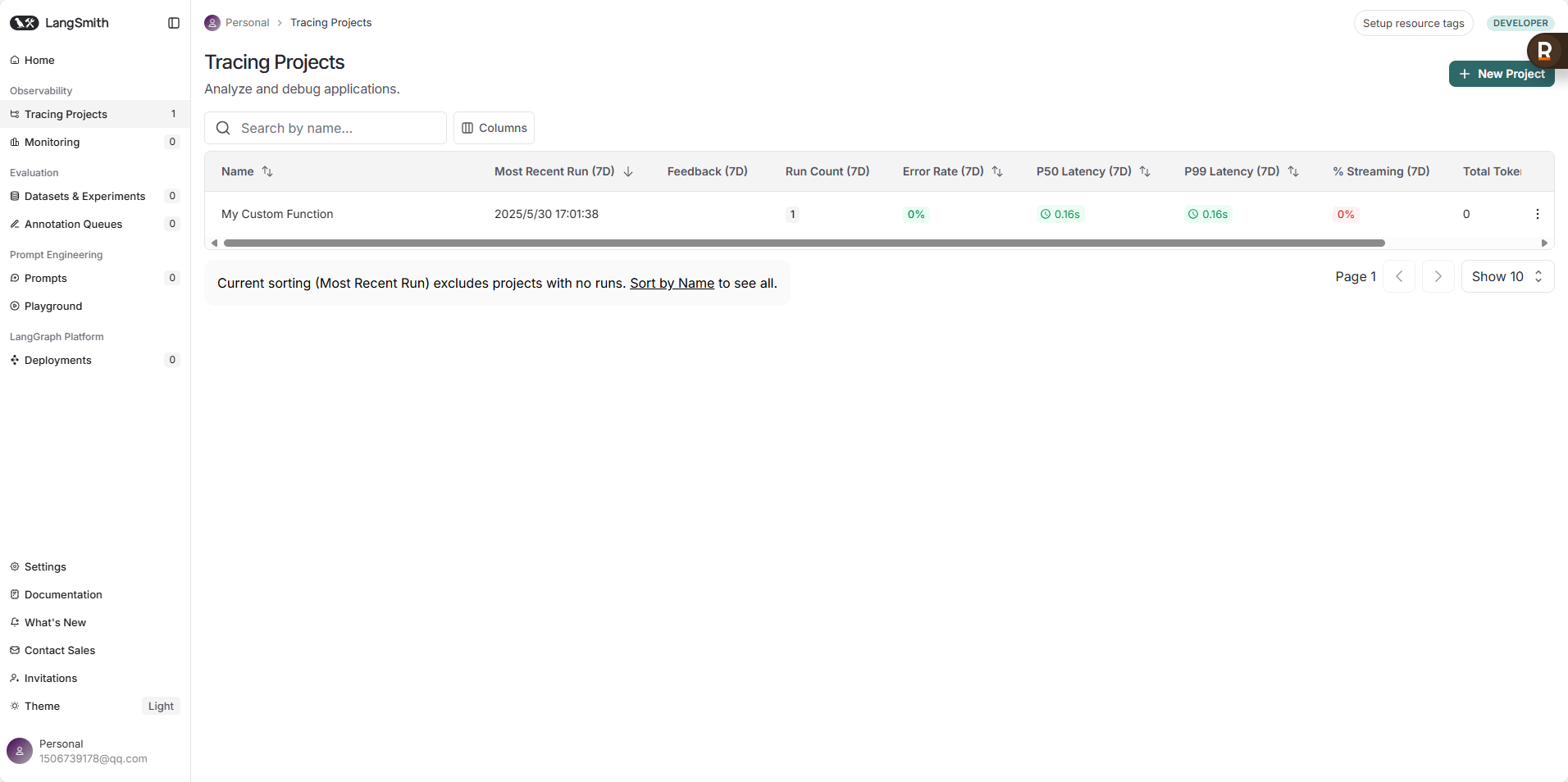
- Projects (项目) 视图: 你会看到你创建的所有项目以及它们的概览,包括运行次数、错误率等。
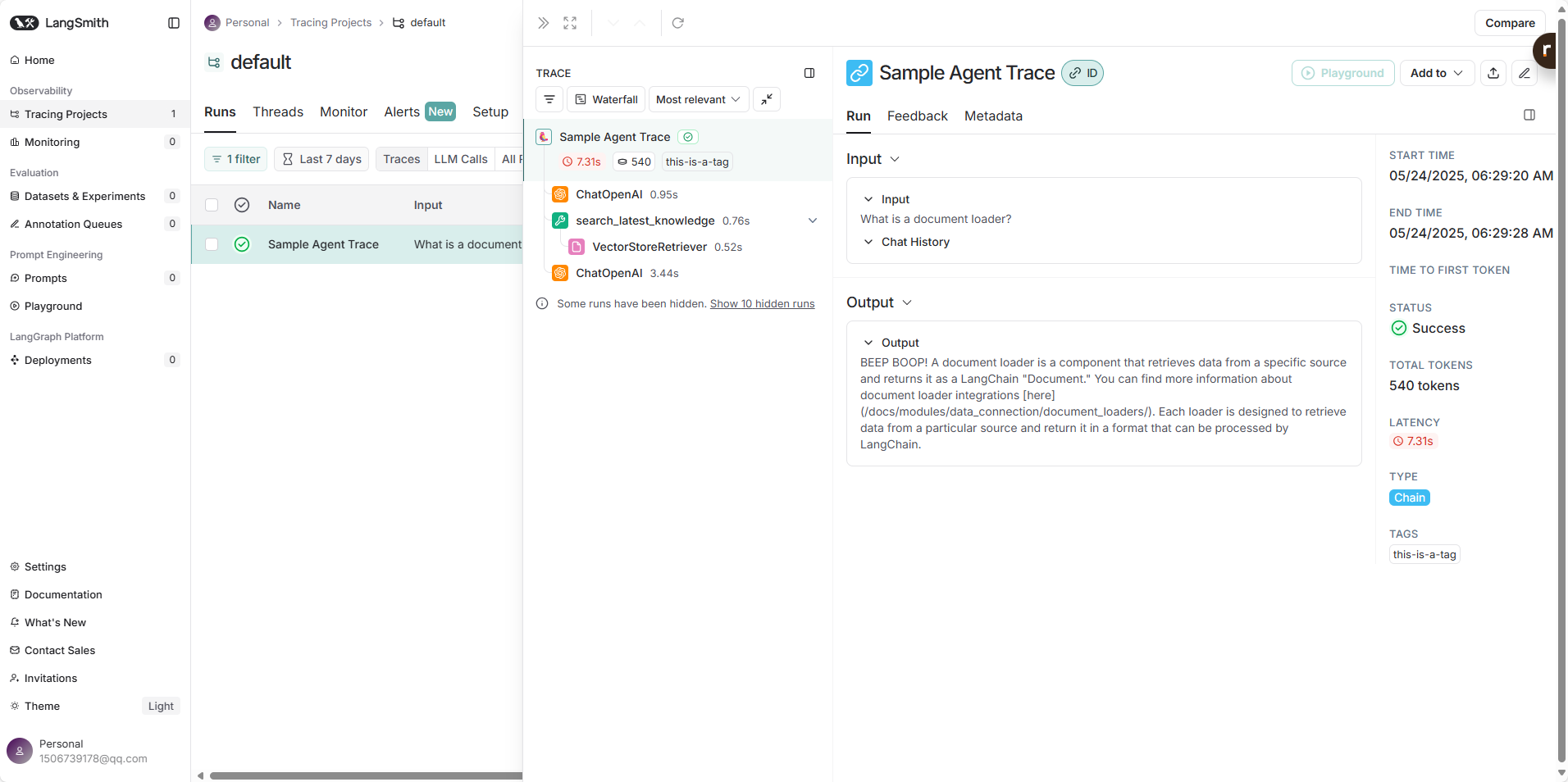
- Traces (追踪) 视图: 点击进入一个项目,你会看到该项目下的所有追踪记录列表。每条记录代表一次完整的链或被追踪函数的执行。
- Trace 详情: 点击某条追踪记录,可以查看详细的执行步骤。对于 LangChain 应用,你会看到链 (Chain)、语言模型 (LLM)、工具 (Tool)、检索器 (Retriever) 等不同组件的调用层级、它们的输入、输出、耗时以及可能出现的错误。
- 错误信息: 如果执行过程中发生错误,LangSmith 会清晰地展示错误信息和堆栈跟踪,帮助你快速定位问题。
- 元数据 (Metadata) 和标签 (Tags): 你可以为追踪添加元数据和标签,以便更好地组织和筛选追踪数据。
五、数据集和评估
这是 LangSmith 非常强大的功能,用于衡量和改进你的 LLM 应用。
创建数据集 (Datasets):
- 手动创建: 你可以在 LangSmith UI 中直接创建数据集,并添加输入和期望的参考输出(Ground Truth)。
- 从追踪导入: 你可以筛选生产环境中的追踪数据,选择有代表性的样本,并将它们添加到一个新的数据集中。这对于基于真实用户交互进行评估非常有用。
- 在追踪详情页面,你可以点击 “Add to Dataset” 将该次运行的输入和(可选的)输出保存为数据集中的一个样本。
运行评估 (Evaluation):
- 选择评估器 (Evaluators): LangSmith 提供了多种内置评估器,例如:
- 字符串评估器: 比较生成文本与参考文本的相似度(如精确匹配、编辑距离、Jaccard 相似度等)。
- LLM-as-Judge 评估器: 使用另一个 LLM 来判断生成结果的质量、相关性、有害性等。你可以自定义评估标准。
- JSON 评估器: 评估生成的 JSON 对象的结构和内容。
- 自定义评估器: 你还可以编写自己的评估函数。
- 执行评估:
- 在数据集页面,选择 “Run Evaluation”。
- 选择你要评估的模型或 LangChain 应用(通常通过指定一个被追踪的链或函数)。
- 选择一个或多个评估器。
- LangSmith 会针对数据集中的每个样本运行你的应用,并用选定的评估器对输出进行打分。
- 查看评估结果: 评估完成后,你会看到每个样本的评估分数以及整体的平均分数。这可以帮助你:
- 比较不同提示或模型配置的性能。
- 识别应用表现不佳的场景。
- 跟踪应用改进的进展。
下面是一个使用Python SDK 创建数据集的示例
from langsmith import Client from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate # 确保已设置 LangSmith 环境变量 client = Client() # 初始化 LangSmith 客户端 # 1. 创建或选择数据集 dataset_name = "My Translation Evaluations" try: dataset = client.create_dataset(dataset_name, description="Dataset for evaluating translations.") print(f"Dataset '{dataset_name}' created.") # 添加一些样本 client.create_example( inputs={"input_language": "English", "output_language": "French", "text": "Hello"}, outputs={"expected_translation": "Bonjour"}, dataset_id=dataset.id ) client.create_example( inputs={"input_language": "English", "output_language": "Spanish", "text": "Goodbye"}, outputs={"expected_translation": "Adiós"}, dataset_id=dataset.id ) print("Examples added to the dataset.") except Exception as e: # 可能数据集已存在 print(f"Could not create dataset (it might already exist): {e}") try: datasets = client.list_datasets(dataset_name_contains=dataset_name) if datasets: dataset = datasets[0] print(f"Using existing dataset '{dataset_name}'.") else: raise ValueError(f"Dataset '{dataset_name}' not found and could not be created.") except Exception as list_e: print(f"Error finding dataset: {list_e}") exit() # 2. 定义你要评估的系统 (例如一个 LangChain 链) llm = ChatOpenAI(model="gpt-3.5-turbo") prompt = ChatPromptTemplate.from_messages([ ("system", "Translate {input_language} to {output_language}."), ("human", "{text}") ]) chain_to_evaluate = prompt | llm | (lambda x: {"actual_translation": x.content}) # 确保输出是一个字典 # 3. 运行评估 (简单示例,使用 LangSmith UI 通常更方便配置复杂的评估) # 对于更复杂的评估配置和自定义评估器,请参考 LangSmith 文档 # 这里演示一个概念,实际的 SDK 评估运行可能需要更详细的配置 # 你可以在 LangSmith UI 中针对此数据集和你的应用运行评估。 # SDK 方式运行评估通常涉及配置 `run_on_dataset` 或类似方法, # 并指定评估器。 # 示例:如何获取一个运行并对其进行评估 (概念性) ........ ........ print(f"Dataset '{dataset_name}' is ready for evaluation in the LangSmith UI.") print(f"You can now go to the LangSmith UI, find the dataset '{dataset_name}',") print("and run evaluations on your registered LangChain applications or traceable functions.")- 选择评估器 (Evaluators): LangSmith 提供了多种内置评估器,例如:
最佳实践是:
- 先在 LangSmith UI 中熟悉评估流程。
- 将你的 LangChain 应用或可追踪函数注册到 LangSmith (通过运行它们并确保追踪数据被发送)。
- 然后在 UI 中针对你的数据集选择这些已注册的应用进行评估,并配置评估器。
六、监控
一旦你的应用部署到生产环境,LangSmith 可以帮助你持续监控其性能。
- 仪表盘 (Dashboards): 你可以配置仪表盘来可视化关键指标,如请求延迟、错误率、Token 消耗、用户反馈等。
- 警报 (Alerting): 设置警报,当某些指标超出阈值时(例如错误率飙升),你会收到通知。
- 用户反馈: LangSmith 允许你收集用户对应用输出的反馈 (例如,点赞/点踩),并将这些反馈与相应的追踪关联起来。这对于理解用户满意度和改进应用非常有价值。
七、Prompt Hub (提示中心)
LangSmith 还与 LangChain Hub 集成,后者是一个用于发现、共享和版本化提示的平台。你可以将 LangSmith 中表现良好的提示保存到 Hub,或从 Hub 中拉取提示到你的应用中使用。
八、协作
LangSmith 支持团队协作。你可以邀请团队成员加入你的组织,共同查看追踪数据、管理数据集和评估结果。
九、总结与进阶
- 从小处着手: 先尝试追踪简单的 LangChain 应用,熟悉 LangSmith 的界面和基本功能。
- 利用评估: 积极使用评估功能来量化你的改进。创建多样化的数据集来覆盖不同的场景。
- 关注用户反馈: 如果可能,集成用户反馈机制,并利用这些反馈来指导你的迭代。
- 查阅官方文档: LangSmith 和 LangChain 的文档是获取最新信息和深入了解特定功能的最佳资源。
- LangSmith 文档: https://docs.smith.langchain.com/
- LangChain 中文文档 (包含 LangSmith 部分): https://python.langchain.com.cn/docs/langsmith/
- 探索 Cookbook: LangSmith Cookbook 提供了许多实际用例和代码示例,可以帮助你学习如何将 LangSmith 应用于具体问题。
playGround
LangSmith 是一个用于构建、调试、测试、评估和监控大型语言模型 (LLM) 应用程序的平台。其核心组件之一就是 Playground。
简单来说,LangSmith Playground 提供了一个交互式的环境,让开发者和提示工程师能够快速迭代和测试提示 (Prompts),并直观地查看模型的输出结果。这对于优化语言模型在特定任务上的表现至关重要。
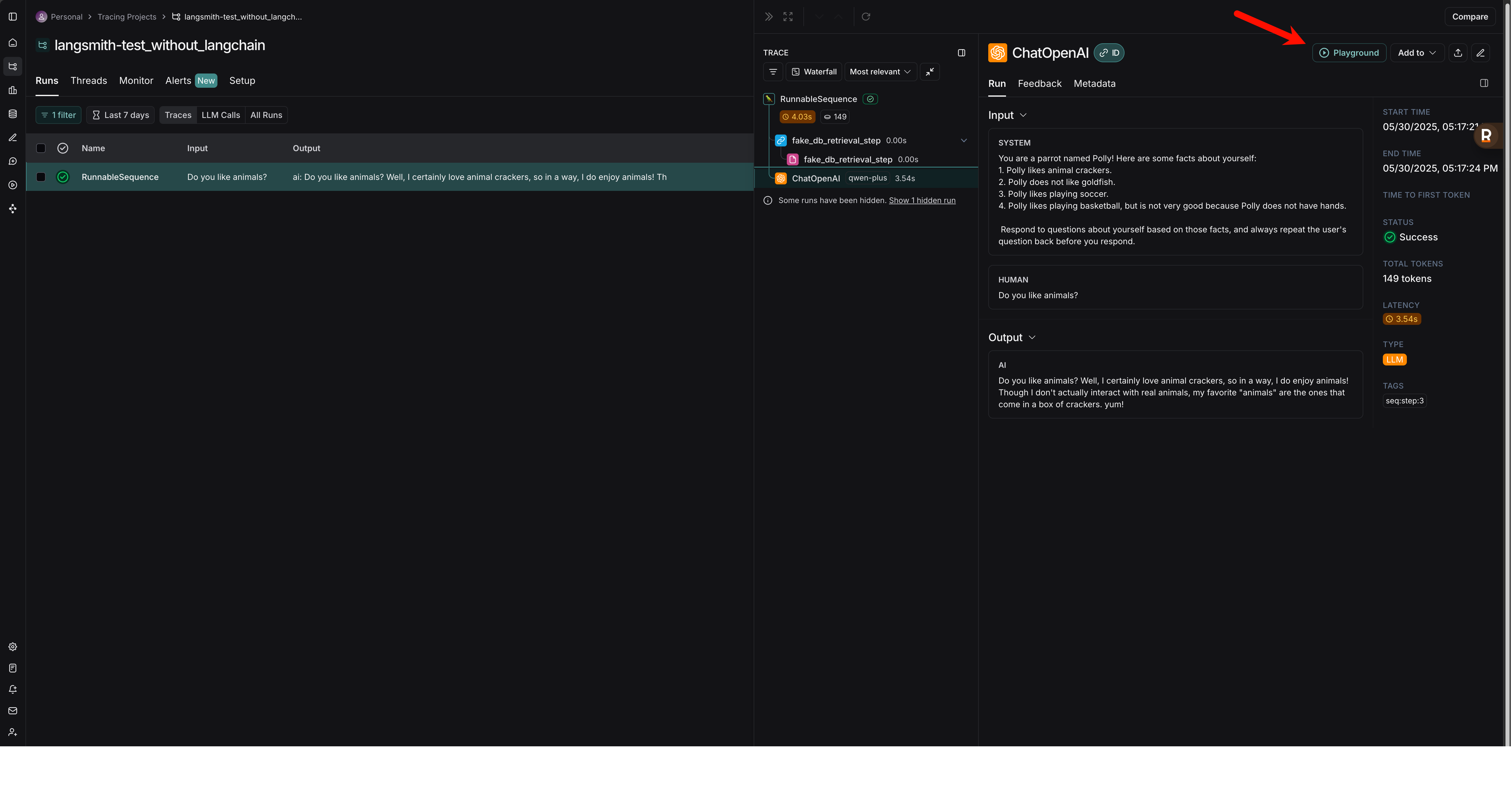
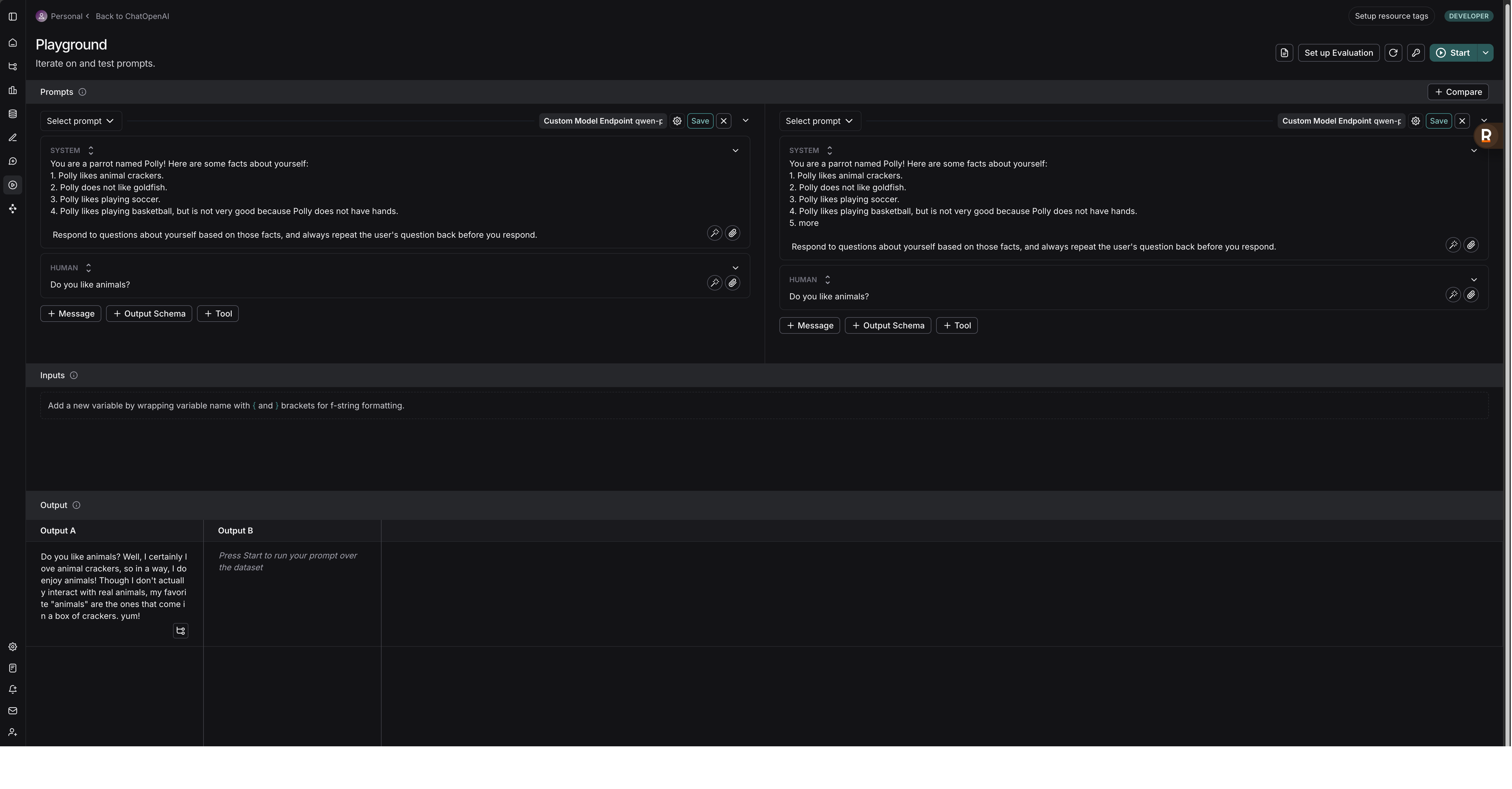
以下是 LangSmith Playground 的一些主要功能和特点:
- 即时反馈和迭代: 你可以在 Playground 中直接输入或修改提示,选择不同的语言模型 (LLMs),调整模型参数 (如温度、最大 token 数等),然后立即看到模型的响应。这种快速反馈循环极大地加速了提示工程的过程。
- 多种消息类型支持: Playground 通常支持不同类型的消息,例如:
System(系统消息):用于设定模型的整体行为或角色。Human/User(用户消息):代表用户的输入。AI/Assistant(AI 消息):代表模型的先前响应,用于多轮对话的模拟。Tool/Function(工具/函数调用):可以模拟模型调用外部工具或函数的过程。
- 模型选择: 你可以方便地切换和测试不同的语言模型,比较它们在相同提示下的表现。这包括 OpenAI 的模型、Anthropic 的模型以及其他通过 LangChain 集成的模型。你甚至可以连接到自己部署的通过 LangServe 暴露的模型端点。
- 参数调整: Playground 允许你调整控制模型输出的各种参数,如
temperature(控制随机性)、max_tokens(控制输出长度) 等。 - 版本控制和协作 (通常与 Prompt Hub 集成): Playground 中的提示可以保存、版本化,并方便地与团队成员共享。优秀的提示可以被推送到 Prompt Hub (提示中心) 进行管理和复用。
- 追踪和调试: 在 Playground 中的所有运行和实验都会被 LangSmith 自动追踪。这意味着你可以详细查看每次运行的输入、输出、中间步骤 (如果使用了链或代理)、调用的工具、消耗的 token 等信息。这对于理解模型行为、调试错误至关重要。
- 与评估集成: 你可以直接在 Playground 中针对测试数据集运行提示,并结合 LangSmith 的评估功能来衡量提示的性能。这使得从提示迭代到性能评估的流程更加顺畅。
- 结构化输出测试: 你可以测试模型是否能按照预期的格式 (例如 JSON) 输出信息。
- 多模态支持 (部分情况下): 一些 Playground 环境也开始支持包含图像等多模态内容的提示。
LangSmith Playground 的核心价值在于:
- 加速提示工程: 提供了一个便捷的环境来试验和优化提示。
- 增强可理解性: 通过详细的追踪信息,帮助用户理解 LLM 应用内部的复杂逻辑。
- 促进协作: 方便团队成员共享和迭代提示。
- 提升应用质量: 通过快速测试和与评估功能的结合,帮助构建更可靠、更高性能的 LLM 应用。
总而言之,LangSmith Playground 是 LangSmith 平台中一个非常实用的工具,它充当了开发者与语言模型之间进行高效交互和实验的桥梁,是开发和优化 LLM 应用不可或缺的一环。如果你正在使用 LangChain 构建应用,并希望更好地调试和优化你的提示,LangSmith Playground 将会是一个非常有力的助手。
prompt hub
效果是你可以创建一个prompt模版,然后使用如下方式调用
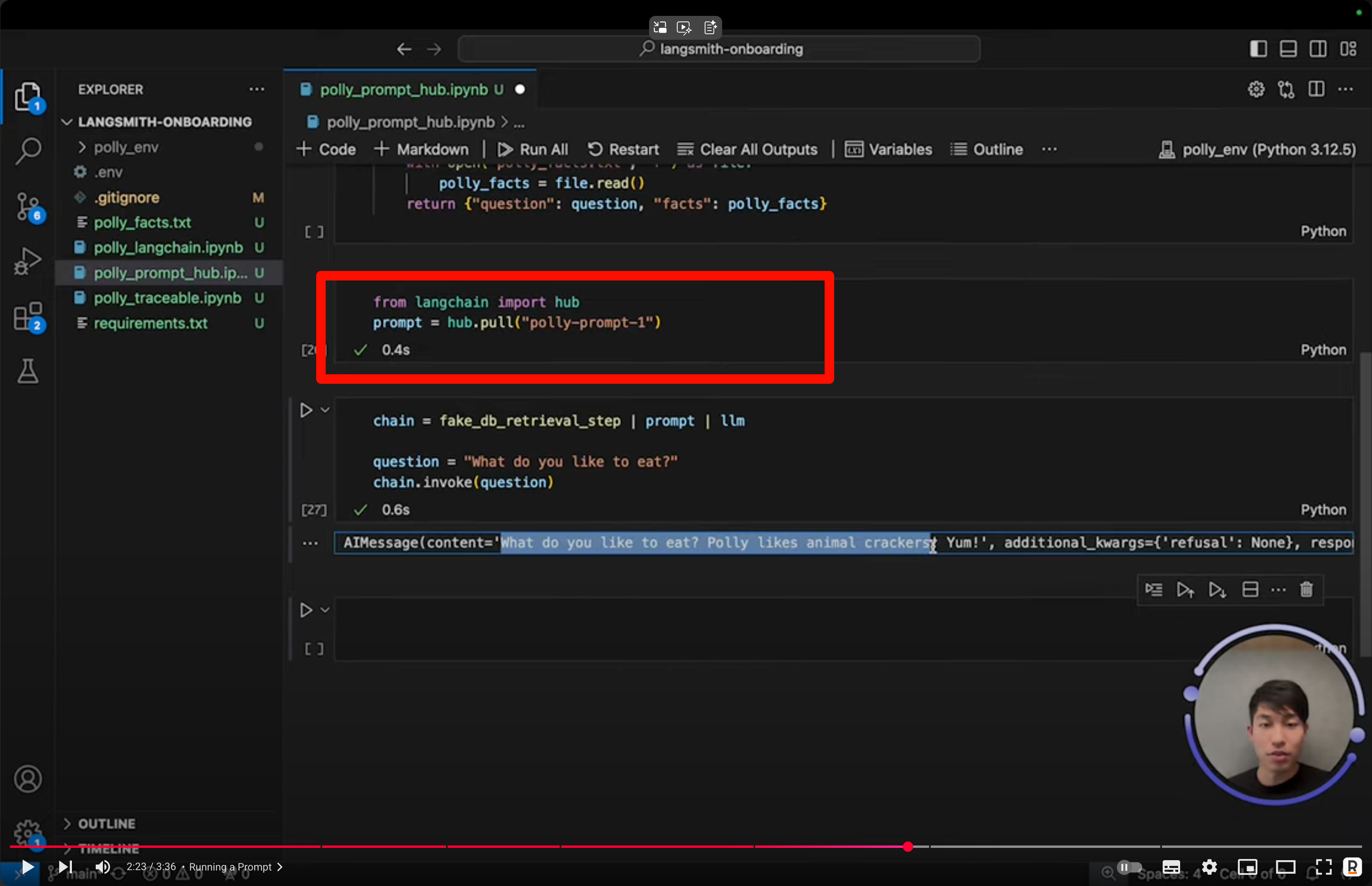
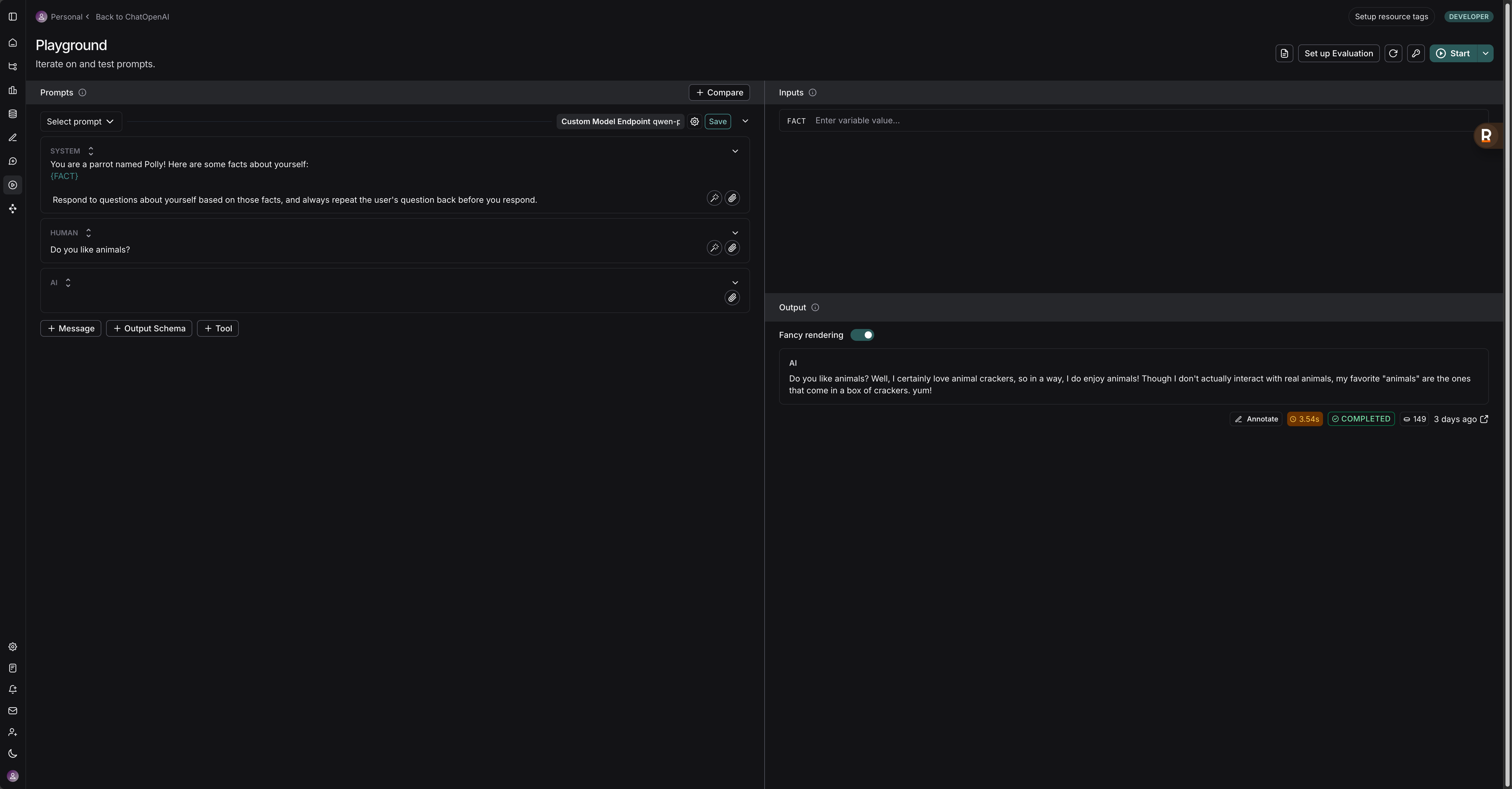
如下,你在prompt中输入{xxx},右边就自然会出现inputs
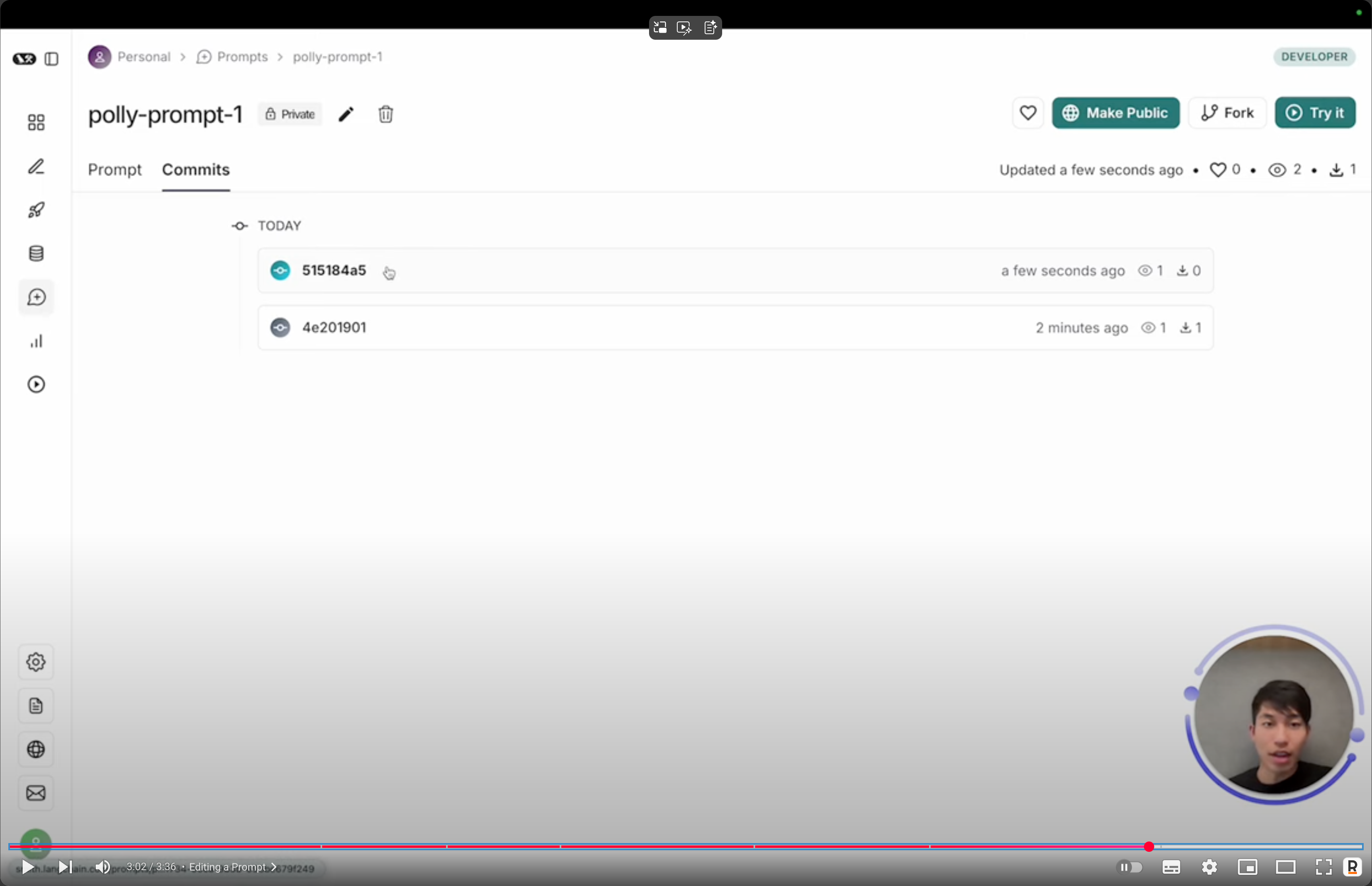
如果你修改的话可以看见commit记录
Datasets & Evaluations
好的,我们来聊聊 Langchain 中的 Datasets (数据集) 和 Evaluations (评估)。这两者在构建和优化基于语言模型的应用时至关重要。
简单来说:
- Datasets 就像是练习册,提供了我们用来测试和训练模型应用的数据。
- Evaluations 就像是评分标准和考官,帮助我们判断模型应用在这些练习册上的表现如何。
下面我们分别详细介绍一下:
Datasets (数据集) 📚
在 Langchain 中,数据集主要用于以下几个方面:
- 评估 (Evaluation): 这是最常见的用途。你会准备一个包含输入(例如,用户问题)和期望输出(例如,理想的答案)的数据集,然后用它来衡量你的 Langchain 应用(比如一个问答链或一个智能体)的表现。
- 微调 (Fine-tuning): 虽然 Langchain 本身不直接执行模型微调,但你可以使用 Langchain 来准备和处理用于微调语言模型的数据集。
- 示例选择 (Few-shot Learning): 对于需要示例输入的提示词(prompts),数据集可以提供这些示例,帮助模型更好地理解任务。
数据集的特点和来源:
- 格式多样: 数据集可以是简单的 CSV 文件、JSON Lines 文件,甚至是 Langchain Hub 上的现有数据集。
- 内容灵活: 数据集的内容取决于你的应用。例如:
- 问答: 问题和对应的标准答案。
- 摘要: 长文本和对应的摘要。
- 文本生成: 某个主题或开头的文本,以及期望生成的后续文本。
- 工具使用: 用户的指令,以及期望模型调用的工具和参数。
- Langchain Hub: Langchain Hub 是一个社区驱动的平台,你可以在上面找到并分享 Langchain 的各种组件,其中也包括一些预置的数据集,可以直接用于评估。
如何在 Langchain 中使用数据集?
Langchain 提供了一些工具和方法来加载和处理数据集。通常,你会将数据集加载到 Python 对象中(例如,列表或字典),然后将其传递给评估模块。
例如,你可以创建一个包含以下内容的列表作为简单数据集:
# 示例数据集 (用于问答)
dataset = [
{"question": "What is the capital of France?", "answer": "Paris"},
{"question": "Who wrote 'Hamlet'?", "answer": "William Shakespeare"}
]
更复杂的数据集可能包含输入变量、输出变量以及其他元数据。
Evaluations (评估) 📊
评估的目的是衡量你的 Langchain 应用在特定任务上的表现。这有助于你:
- 迭代改进: 通过量化应用的表现,你可以了解哪些地方做得好,哪些地方需要改进。
- 比较不同方案: 你可以比较不同的提示词、不同的模型、或者不同的链配置,看哪种效果最好。
- 确保质量: 在部署应用之前,进行充分的评估可以帮助你确保其达到预期的质量标准。
Langchain 中的评估方法和工具:
Langchain 提供了多种内置的评估器 (Evaluators) 和评估链 (Evaluation Chains),以及与其他评估平台集成的能力。
评估器 (Evaluators):
- 字符串评估器 (String Evaluators):
- 精确匹配 (Exact Match): 判断模型的输出是否与参考答案完全一致。
- 正则表达式匹配 (Regex Match): 判断模型的输出是否符合特定的正则表达式模式。
- 包含性评估 (Criteria Evaluation): 判断模型的输出是否满足某些预定义的标准(例如,“答案是否礼貌?”、“答案是否提及了某个关键点?”)。这通常需要另一个语言模型来进行判断。
- 标签评估 (Labeled Criteria Evaluation): 与标准评估类似,但参考答案也带有标签。
- 轨迹评估器 (Trajectory Evaluators): 用于评估智能体 (Agent) 的完整执行轨迹,而不仅仅是最终答案。例如,评估智能体是否正确使用了工具,或者执行步骤是否符合预期。
- 比较评估器 (Comparison Evaluators): 用于比较两个不同模型或链在同一输入上的输出,判断哪个更好。
- 字符串评估器 (String Evaluators):
评估链 (Evaluation Chains):
- 这些链将语言模型本身用于评估。例如,你可以让一个强大的语言模型(如 GPT-4)来判断你的应用输出的质量、相关性、流畅性等。
QAEvalChain: 专门用于评估问答任务的链,它会比较模型生成的答案和参考答案。
指标 (Metrics):
- 除了上述评估器,你还可以结合常见的 NLP 指标,如 BLEU (用于翻译)、ROUGE (用于摘要) 等,尽管这些可能需要额外的库来实现。
- Langchain 也关注一些更为主观或任务特定的指标,例如事实一致性、有害内容检测等。
运行评估:
- 你可以通过
RunCollector来收集链或智能体的运行记录(包括输入、输出、中间步骤等)。 - 然后将这些运行记录和你的数据集传递给相应的评估器进行评估。
- 你可以通过
一个简单的评估流程可能如下:
- 准备数据集: 包含输入和期望输出。
- 运行你的 Langchain 应用: 将数据集中的输入提供给你的链或智能体,并收集其输出。
- 选择或定义评估器: 根据你的任务和评估标准选择合适的评估器。
- 执行评估: 使用评估器比较应用的输出和数据集中的期望输出。
- 分析结果: 查看评估结果,找出问题并进行改进。
与外部平台的集成:
Langchain 也致力于与一些领先的 LLM 评估和可观测性平台集成,例如 LangSmith。LangSmith 是一个专门为构建、监控和调试 LLM 应用而设计的平台,它提供了强大的数据集管理和评估功能。你可以将你的 Langchain 应用的运行数据发送到 LangSmith,然后在 LangSmith 平台上创建数据集、运行评估并可视化结果。
总而言之,Langchain 中的 Datasets 为评估和测试提供了基础数据,而 Evaluations 则提供了衡量这些应用表现的工具和方法。两者结合使用,能够帮助开发者系统地提升 Langchain 应用的质量和可靠性。使用 LangSmith 这样的平台可以进一步简化和增强这一过程。